
OS Notes: Disk and IO
Published:
18.1. IO
- Issue commands to device
- Catch interrupts
- Handle error Diverse, portability, performance
Category
- Block Device
- Info stored in fixed-size blocks, with its own address
- Transfer in one or more blocks
- E. hard disk, CD ROM, USB
- Character Device
- Info sent/received in stream
- Not addressable
- E. mice, printer, network interfaces
Controller and Device
Device expose a finite set of registers to communicate with CPU
- Command buffer for start/stop
- Data buffer that can be read/written
- E. address, size
Communication Methods
1. IO Port Space
Old interface, two address spaces
- IO port, number assigned
- Access with privileged instructions
in portnum, targetout portnum, source
2. Memory-Mapped IO
Mapped to some unique physical offset
- Device listens (snoops) a physical range
Advantages
- Written in C
- No special protection
- Convenient memory interface
Communicate through struct pci_config
- Inspect with
lspci
Need to disable cache!!!
- Through page table
cache_disabledbit
Interrupt
Raise interrupt when device finished work (or wants attention)
- Interrupt controller issues interrupt
- CPU acks interrupt
Messaged Signaled Interrupts
- Pin count restrictions Write a small interrupt-describing data block describing data to a special
mmap()ed IO address triggers interrupt - Very programmable
Precise Interrupts
Simple
- PC saved in known place
- All instructions before fully executed
- All instruction after not executed (or no side effects)
- Execution state of PC known
What if OOO, many instructions in-flight? Which instruction gets interrupted??
IO Software
- Error handling
- Close to hardware as possible
- Sync vs asyn
- Buffering
- Sharable
Performing IO
Programmed IO
- CPU does all work
- Busy-waiting (pooling)
copy_from_user(buffer, p, count);
for (i = 0; i < count; i++) {
while (*printer_status_reg != READY)
;
*print_data_register = p[i];
}
return_to_user();
- Waste CPU cycle
Interrupt-Drive IO
Process blocked while waiting, another process scheduled
- When ready raises interrupt, then copies data
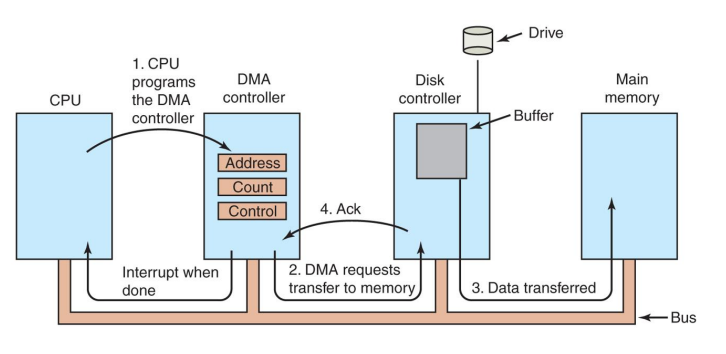
Direct Memory Access (DMA)
Ask DMA controller to move data as a bulk
- Has access to system, but independent from CPU
- When DMA controller moves data, CPU can do something else
- aka “copy core”
- Interrupt when done
Memory Protection
Security concerns
Protection with another translation table: IOMMU
- Similar to page table protects via MMU
- If invalid address, exception raised
Example Devices
Clock
HW
Crystal oscillator + pulse counter + holding register
- Interrupt when counter becomes 0
SW
E. CPU stat, preemption, alarm call, system watchdog (deadlock detection)
When process sleep(10), need to release this process from blocking state after 10 s Create a clock header that wakes a sequence of events
Network Driver
Receive: Network card need to maintain an ring buffer
- Throttle TCP/IP or device, when either side too frequent
- High degree of concurrency
18.2. Storage Devices
HDD
- Cylinder and sector (512b each)
- RW head
New devices expose uniform Logical Block Address
- Disk controller translates LBA to CHS
- OS views as 1D array of sector groups (blocks)
Sequential access much faster than random
Seek Performance
Move to specific track and keep it there
- Need more accurate for write, since errors are catastrophic
- Seeking (track)
- Critical for small loads
- Should to be optimized, schedule requests to shorten seeks
- Move some data to memory: file system caching
- Rotational delay (sector)
- Critical for sequential transfer
- Byte transfer
- Much wasted
Disk Management
Placement/ordering requests
- Make as sequential as possible
- Group as long seeks
- Con: if crash, may leave in inconsistent state
Considerations
- Internal/external fragmentation
- File growth
- Sequential/random access time
- Metadata overhead
1. Contiguous Allocation
FS allocates space all at once
- Space managed by examining bitmap
- Metadata: base, size (simple)
Pros
- Easy, low overhead
- Fast sequential access
Cons
- External fragmentation
- Can move around
- Hard to grow
2. Extent-Based Allocation
Multiple contiguous regions for file (extent)
- ana. memory segmentation
- Metadata: array of (base, size)
3. Linked Allocation
Data block part of linked list
- Metadata for next pointer
Pros
- No external fragmentation
- Similar to paging
- File can grow easily
- Easy to implement
Cons
- Slow sequential access
- Hard to compute random access
- Some overhead
The LL pointers can be stored in a dedicated pointer table
Pros
- Faster random access: FAT lookup
Cons
- Slow sequential
- Need recovery when crash
4. Indexed Allocation
Metadata: Array of pointers (index) to data blocks
- Blocks allocated on demand
- i-nodes
Pros
- No external fragmentation
- Easy growth
- Multiple levels of indexing
- Fast random access
Cons
- Overhead: index blocks
- Slow sequential
Scheduling Disk Requests
1. First Come First Served
Process on the order received
- Easy, fair, but no locality
2. Shortest Positioning Time First
Pick request with shortest seek time
- High locality, throughput
- Starvation
- Don’t know which request fastest
3. Elevator
Sweep across disk, serving all requests passed
- SPTF, but only in one direction
- Switch direction only if no further requests
- Locality, bounded waiting
SSD
Organization
Page -> block -> plane (parallel access) -> die -> chip
Functions
- Read
- Very random! Less power, faster
- Erase
- Program Write takes two steps
Writing
Need to be done at block level
- Backup
- Erase
- Change some pages in memory
- Re-program from memory to SSD
Very expensive!
- May wear down cell!
- Will not write in place, due to wear balancing
In-Memory Map
Keep memory map of logical -> physical page number
- On write, pick unused page, mark previous page free
- Repeated write will remap
Metadata
- Allocated
- Written
- Obsolete
100: after power failure, partially written state
Requires a lot of memory, wastes RAM in host
- Solution: store FTL map in flash itself!
Problem: write amplification
- Small writes to empty blocks will lead to intense fragmentation!
- Must periodically defragment
Disk Scheduling
No seek time for SSD
- No op: pass request directly to device
- MQ-deadline
- Wear Level Focus: coalesce write
RAID
Redundant Array of Independent Disks
- Used as SLED (Single Large Expensive Disk) logically, but each block may parallel IO
Hard Drive Errors
- Checksum error
- Transient
- Permanent: catastrophic
- Seek error: aggressive overshoot
- Programming error: requesting nonexistent sector
- Controller error
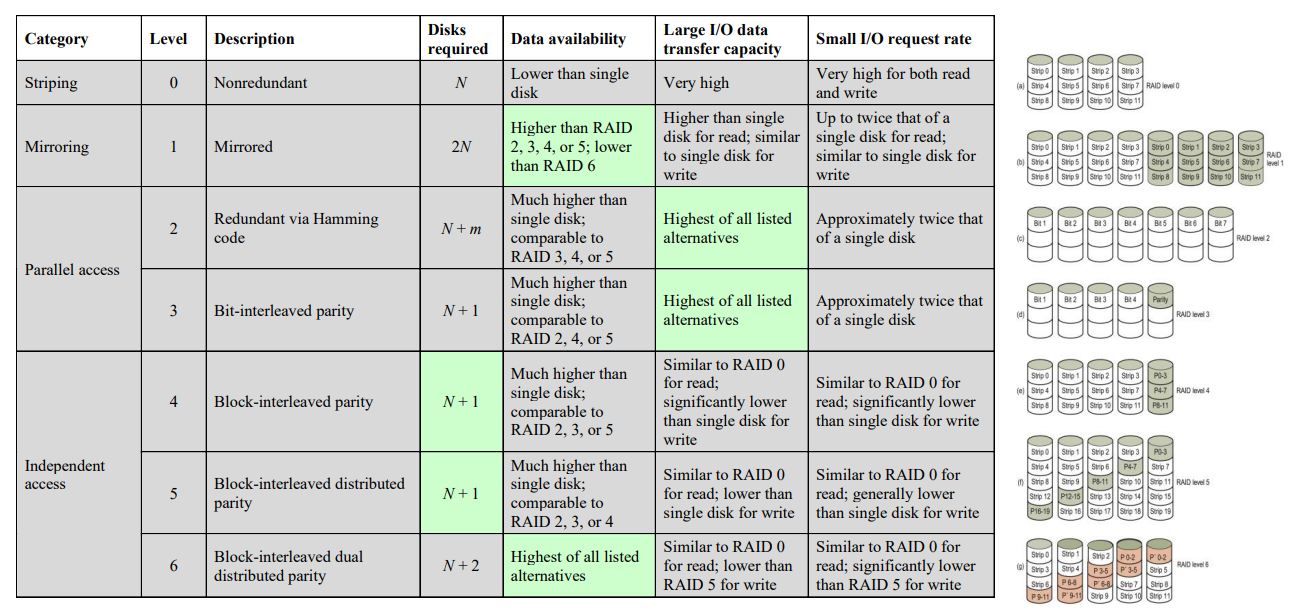
RAID Levels
- Level 0
- No redundancy, just logical partition into strips
- Level 1
- Duplicate all data
- Double the cost :(
- No write penalty (parallelized)
- Level 2
- Data stripping (very small)
- Parallel access
- Use Hamming code for ECC (\(\log(N)\))
- Correct 1 bit, detect 2 bits
- Data stripping (very small)
- Level 3
- Similar to 2, but only single redundant disk
- Independent of disk array size!
- Parallel access
- High data transfer rate, but only one IO at a time
- Similar to 2, but only single redundant disk
- Level 4
- Larger strips
- Bit-by-bit parity strips, all stored in parity disk
- Write penalty when IO
- Level 5
- Level 4, but parity distributed across all disks
- Loss of any one disk is fine
- Level 6
- Two parity calculations, stored in separate blocks on different disks
- Substantial write penalty
Logical Volume Manager
Volume: partition of hard drive
LVM allows combining physical partitions to volume groups logically
- IO requests directed to correct physical disk
19. Linux File System
Original UNIX
- Superblock: sentinel (E. number of blocks, pointer to free list)
- Inode: contiguous block, point to data
- Data
Problem: slow
- Blocks too small
- Index too large
- Transfer rate low
- Poor clustering related objects
lsinefficient- Inode not local to each other
Modern UNIX FS
Multilevel indexed block allocation
- Designed with disk geometry (cylinder groups)
BFS
Partition disk into multiple OSes, or multiple file systems
Top level
- Super block: FS metadata
- Boot block: place bootloader, for hardware
- Cylinder group partitions: contain Inode and data blocks
- Minimize disk seeks
Allocation goals
- Sequential blocks in adjacent sectors
- Inode the same cylinder group as file data
- Inodes in a directory in same cylinder group
Cylinder group
- Metadata: super block/CG info
- Inode bitmap
- Block bitmap
- Inodes (128 B each)
- Data blocks (4 KB each)
Reserve scattered empty spaces for near allocations
Inode
One Inode for one file, uniquely identified
Directory: also a file, with Inode and data blocks
- One dentry per file, with filename and Inode pointer
See via
ls -i
Has direct data block pointers, single indirect, double indirect, …
Extent-based: contiguous mapping of certain blocks on the physical disk
Linking
Static Linking
aka hard link
ln orig_file new_file
ln -p orig_file new_file
- Two filenames pointing to the same I-node
File deleted only after all references deleted
Restrictions
- Can’t link to other FS
- Can’t link to directories (circular)
Symbolic Linking
Special file, data is the name/path to another file
- The name doesn’t need to exist, since not pointing to I-node
- Symbolic link has its own I-node
- Extra overhead, since need to open twice
ln -s orig_file new_file
Syscalls
Reading file
struct stat *statbuf; // modes, number of links, ID, ...
int stat(const char *pathname, struct stat *statbuf);
int fstat(int fd, struct stat *statbuf);
int lstat(const char *pathname, struct stat *statbuf); // for ls
Reading directory
struct *dirent; // single entry information
DIR *opendir(const char *name); // open directory, get opaque handler
struct dirent *readdir(DIR *dirp);
DIR *dir;
struct dirent *entry;
dir = opendir("/");
while ((entry = readdir(dir)) != NULL))
printf(" %s\n", entry->d_name);
closedir(dir);
For ls -ls, open file, and do lstat on that
LFS: Log-structured FS
Disk caching optimized, so most seeks are writes. LFS optimizes writes
Buffer writes within memory. Once full, write to a log (checkpoint)
- Segment write is sequential, fast
Read still random, but mostly handled by cache
- Problem: scatter I-nodes
- Need an I-node map pointing to I-nodes
- Map is cached, and has fixed disk location
Kernel runs a cleaner thread
- Treat disk as a circular buffer
- If crash in-between, losing data
Avoid overhead
- Group old data in the same segment
- Avoid strict circular log, but a list of segments
Segment
Inode interleaved with data
- Need store identity of I-node, block
Crashes
Assume write happens atomically
- B: I-node bitmap update
- I: I-node added
- D: Dentry added to directory data block
fsck: File System Consistency Check
Very long time
- Can’t fix all senarios, such as
B'I D'
Block Consistency
- Consistent: either in free list or used list
- Missing block: add it back to free list
- Duplicate free blocks: fix free list
- Duplicate used blocks fpointed by 2 I-nodes: make a copy
Journaling
Keep a log of my actions, before updating FS
If crash in the middle, replay the log
- Better than
fsck- Commit dirty blocks to journal
- Write commit
- Write to actual disk
- Free journal space
Still expensive. Need two disk writes
- Data journaling: all writes, expensive
- Metadata journaling: only metadata
- Ordered journal: write file to FS first, then journal metadata
- Possible inconsistency
Virtual FS
Various FS under UNIX
Interface: open(), close(), read(), etc.
- Does not expose implementation details
Creation
mkfs -t ext3 /dev/sda6
- Creates an
ext3FS on partitionsda6 - Will wipe out all existing data
Mounting
mount -t type device directory
- Hard disk mounted to
/ - Other FS (E. temp, network) …
Data Structures
struct file: instance of open file
- Per-process fdtable entry, allowing sharing by copying file pointer
- Flags, current position
struct dentry: hard link that contains link and inode number
- Break absolute path into dentries
- Expensive path resolution, need recursive find
struct inode
HW7
const struct inode_operations *i_op
- Interface to read, write, seek, …
struct super_block: descriptor of a mounted FS
- Journaling
Change scheduling algorithm for a particular disk device
HW6
Device Drivers
Interface between specific hardware from software
- Loaded through Loadable Kernel Modules (LKMs)
- Virtual files, can be interacted with syscalls
open(),read()- Functions specified in
struct file_operations
- Functions specified in
- Device type (from
stat <file>): major and minor number
E. /dev/nullzero
static struct file_operations fops = {
.owner = THIS_MODULE,
.open = nullzero_open,
.read = nullzero_read,
.write = nullzero_write,
.release = nullzero_release, // Called during `close()`
.unlocked_ioctl = nullzero_ioctl, // called during ioctl()
};
static int nullzero_open(struct inode *ino, struct file *fp) { return 0; }
static int nullzero_release(struct inode *ino, struct file *fp) { return 0; }
static ssize_t nullzero_read(struct file *fp, char __user *buf,
size_t len, loff_t *off);
static ssize_t nullzero_write(struct file *fp, const char __user *buf,
size_t len, loff_t *off);
fp->private_datais a genericvoid *to store per-open state information
ioctl()
Syscall whose behavior can be specified per device
- Fall out of scope of
read()andwrite(), for larger device control
#define NULLZERO_IOC_SET_CHAR _IOW(NULLZERO_IOC_MAGIC, 1, char)
static long nullzero_ioctl(struct file *filep,
unsigned int cmd, unsigned long arg) {
char new_c;
switch (cmd) {
case NULLZERO_IOC_SET_CHAR:
if (get_user(new_c, (char __user *)arg)) // Similar to `copy_from_user()`
return -EFAULT;
c = new_c;
break;
default:
return -ENOTTY; // "Not a typewriter"; for invalid `ioctl()`
}
return 0;
}
HW7
Check out awesome diagrams from prev. Head TA Alex!
VFS
Virtual File System, API for an FS
Idea: Userspace open() call triggers a syscall in kernel
- Depending on things open, different syscall
- We need to implement a set of operations (
ezfs_open())- Do lower-level stuff, also handled by VFS
fs/bfs/inode.c
static struct file_system_type bfs_fs_type = {
.owner = THIS_MODULE,
.name = "bfs",
.mount = bfs_mount,
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV,
};
Init and exit
static int __init init_bfs_fs(void)
{
int err = init_inodecache();
if (err)
goto out1;
err = register_filesystem(&bfs_fs_type);
if (err)
goto out;
return 0;
out:
destroy_inodecache();
out1:
return err;
}
static void __exit exit_bfs_fs(void)
{
unregister_filesystem(&bfs_fs_type);
destroy_inodecache();
}
register_filesystem()andunregister_filesystem(), passing thestruct bfs_fs_type
For ramfs
static struct file_system_type ramfs_fs_type = {
.name = "ramfs",
.init_fs_context = ramfs_init_fs_context,
.parameters = ramfs_fs_parameters,
.kill_sb = ramfs_kill_sb,
.fs_flags = FS_USERNS_MOUNT,
};
int ramfs_init_fs_context(struct fs_context *fc)
{
struct ramfs_fs_info *fsi;
fsi = kzalloc(sizeof(*fsi), GFP_KERNEL);
if (!fsi)
return -ENOMEM;
fsi->mount_opts.mode = RAMFS_DEFAULT_MODE;
fc->s_fs_info = fsi;
fc->ops = &ramfs_context_ops;
return 0;
}
- Look at
fc->opsstatic const struct fs_context_operations ramfs_context_ops = { .free = ramfs_free_fc, .parse_param = ramfs_parse_param, .get_tree = ramfs_get_tree, }; .kill_sbkills the super blockvoid ramfs_kill_sb(struct super_block *sb) { kfree(sb->s_fs_info); kill_litter_super(sb); }
Operations
static const struct super_operations bfs_sops = {
.alloc_inode = bfs_alloc_inode,
.free_inode = bfs_free_inode,
.write_inode = bfs_write_inode,
.evict_inode = bfs_evict_inode,
.put_super = bfs_put_super,
.statfs = bfs_statfs,
};
struct super_block
bfs_fill_superreads superblock, put inbfs_sb- Each data field manually set
s->s_rootcreated
Filling struct super_block
- Metadata: file size, etc.
s_active: whether or not FS is mounted or notstruct block_device *s_bdev: point to underlying HW device FS is using- For us, loop device (emulated block device)
VFS structs
Super block
struct super_block {
unsigned long s_magic; /* filesystem’s magic number */
struct dentry *s_root;
struct super_operations s_op;
void *s_fs_info; // points to struct super_block
};
struct inode {
struct inode_operations *i_op; // metadata
struct file_operations *i_fop; // data
unsigned int i_nlink;
blkcnt_t i_blocks;
umode_t i_mode;
void *i_private; /* fs private pointer
}
struct ezfs_super_block {
uint64_t magic;
uint64_t disk_blks;
DECLARE_BIT_VECTOR(free_inodes, EZFS_MAX_INODES);\
DECLARE_BIT_VECTOR(free_data_blocks, EZFS_MAX_DATA_BLKS);\
struct mutex *ezfs_lock;
};
struct ezfs_sb_buffer_heads {
struct buffer_head *sb_bh; // ->b_data
struct buffer_head *i_store_bh;
};
struct ezfs_inode {
unsigned int nlink;
uint64_t nblocks;
uint64_t direct_blk_n;
uint64_t indirect_blk_n;
};
struct ezfs_dir_entry {
uint64_t inode_no;
uint8_t active;
char filename[EZFS_FILENAME_BUF_SIZE];
};
Functions
1. fill_super()
Fills RAM
sbwith diskmy_sb
struct super_block {
unsigned long s_magic; /* filesystem’s magic number */
struct dentry *s_root;
struct super_operations s_op;
void *s_fs_info; // points to struct super_block
};
- Set
sbblocksizesb->set_blocksize(sb, EZFS_BLOCK_SIZE); - Allocate buffer heads and connect to
sb->s_fs_infoto it- Get
bh->sb_bhandbh->i_store_bh struct ezfs_super_block my_sb = bh->sb_bh->b_data- Check and populate
magic
struct ezfs_sb_buffer_heads *bh = kmalloc(/*...*/); sb->s_fs_info = bh; bh->sb_bh = sb_bread(sb, 0); bh->i_store_bh = sb_bread(sb, 1); struct ezfs_super_block *my_sb = bh->sb_bh->b_data; sb->s_magic = my_sb->magic; - Get
- Create root inode
struct inode *root_ino = ezfs_get_inode(sb, 1); sb->s_root = d_make_root(root_ino);
get_inode()
Gets RAM
inode, given an inode number
struct inode {
struct inode_operations *i_op; // metadata
struct file_operations *i_fop; // data
unsigned int i_nlink;
blkcnt_t i_blocks;
umode_t i_mode;
void *i_private; /* fs private pointer
};
- Get RAM
inode, return if already existsstruct inode *in = iget_locked(sb, ino); if (!(in->i_state & I_NEW)) return ... unlock_new_inode(ino); - Get disk inode, and connect
struct ezfs_sb_buffer_heads *bh = sb->s_fs_info; struct ezfs_inode *my_in = (struct ezfs_inode *)(bh->i_store_bh->b_data) + (ino - 1); in->i_private = my_in; - Set mode, metadata, etc.
i_blocksneeds to be multiplied
- Connect function
structs forinode_operationsandoperations
evict_inode()
Called when deleting file, or kernel VFS evicting buffer
- If link count = 0
- Free all data block (direct/indirect walk)
- Free inode in superblock bitmap
- Cleanup VFS data structures
truncate_inode_pages_final(&inode->i_data); invalidate_inode_buffers(inode); clear_inode(inode);
get_block()
Caches block into kernel VFS through
map_bh()
static int ezfs_get_block(struct inode *inode, sector_t block,
struct buffer_head *bh_result, int create)
- Get data structures
- Locate
physblock number - Check if physical block is there, and if need create
- Allocate an empty block
- Connect metadata
- Connect actual block metadata
iterate()
Called when
ls
inode = file_inode(fp);- Get direct block number, and
sb_read()it - Emit dots
- Iterate over and emit each one
struct ezfs_dir_entry ezfs_dentry = (struct ezfs_dir_entry *)(bh->b_data) + ctx->pos; for (...) dir_emit(ctx, ezfs_dentry->filename, strlen(...), ezfs_entry->inode_no, UNK);setattr(): usesimple_setattr(), andtruncate_blocks()if neededread_folio(): useblock_read_full_folio
- Further calls
get_block() - A folio handles memory in larger chunks (huge pages)
- Called when cache miss, when reading from the disk -
writepages(): usempage_writepages - Memory->disk, saving data -
write_begin(): useblock_write_begin - Called at the start of user
write() - Prepares kernel folio; allocate one if does not exist -
write_iter(): usegeneric_file_write_iter - Do actual copying -
write_end(): usegeneric_write_end - Cleans up folio and mark it dirty -
write_inode(): connect a few parameters - Called when flushing dirty inode buffer back to disk
lookup()
Called when kernel needs to resolve a single path component within a directory, that’s not yet cached (dentry cache miss)
struct dentry *ezfs_lookup(struct inode *parent_dir, struct dentry *child_dentry,
unsigned int flags)
- Find parent direct data block.
- Iterate dentries. Check file name
- If match found, get
child_dentry->inode_no - Return
d_split_alias(child_inode, child_dentry);- Populates inode metadata from dentry’s mapping
create()
Creates new inode in parent
dir, given already populateddentry
static struct inode *_ezfs_create(struct inode *dir, struct dentry *dentry,
umode_t mode, bool is_dir)
- Read directory entry. Find the next empty dentry slot
- Find empty inode. Initialize new inode and
ezfsinoded_instantiate_new(dentry, new_inode);
- Find empty data block
- For file, no data blocks are created in
create()!
- For file, no data blocks are created in
- Write new dentry to parent dentry’s data block
- Increment parent reference count
unlink()
int ezfs_unlink(struct inode *parent_dir, struct dentry *dentry)
- Iterate dentries. Find filename match
- Zero out that entry
drop_nlink(parent_inode);
mkdir()
int ezfs_mkdir(struct mnt_idmap *idmap, struct inode *dir,
struct dentry *dentry, umode_t mode)
struct inode *inode = _ezfs_create(dir, dentry, mode, true);
rmdir()
- Check if directory is empty
- Unlink (which drops for parent)
drop_nlink()for bothdir(.) andd_inode(dentry)(..)
20. Networking
ana FS, well-defined API that hides details
- Layer 1-4 handled by OS
- Connected via socket
Layer 5-7 (application) handled by user
- App data
- Http data
- TCP Segment/UDP packet
- IP datagram
- Network frame
IP
E2E transmission between machines (not applications)
- Each packet has a maximum size, depends on medium
- Unreliable
Address: 4 bytes
- For public network, need bridge via NAT
- TTL: prevent loops
IPv6 uses longer IP address, with other features 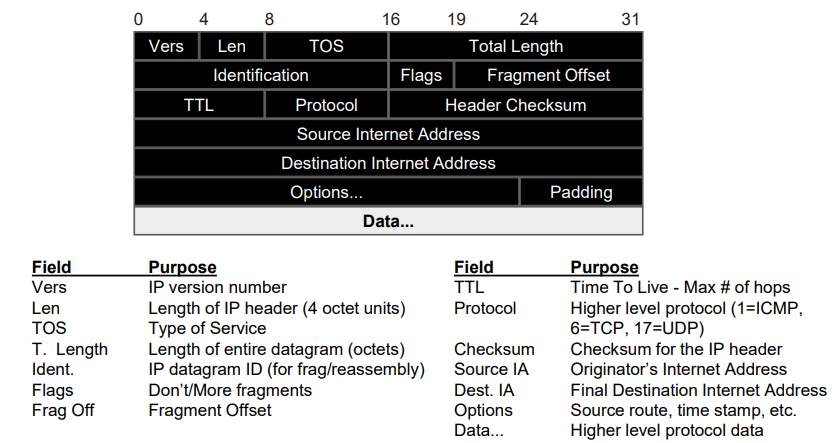
Routing
Routing table forward to the IP address of next-hop, based on target IP
Most devices send everything to a single local router (gateway)
DNS: Domain Name Resolution ARP: Address Resolution Protocol
- Discover link layer address
Network Setup
- Static: stored in FS
- Dynamic: retrieved from DHCP (Dynamic Host Configuration Protocol)
auto eth0
iface eth0 inet dhcp
UDP
IP
- packet length + checksum
- src/dst ports
Allows multiplexing over IP
Application: can tolerate data loss (E. video, games)
TCP
Reliable, connection oriented, stream delivery
- Overheads
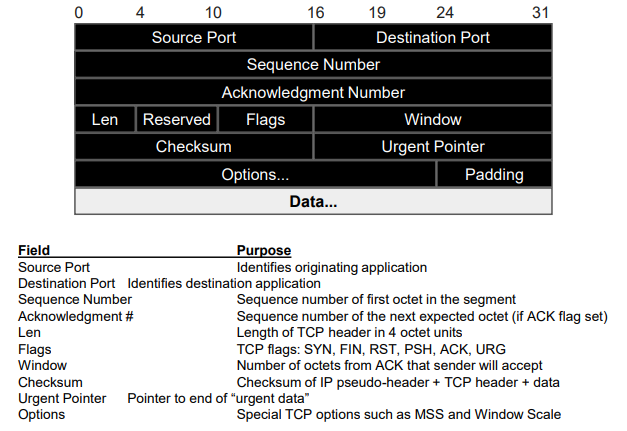
- Need buffer in sender/receiver end
- Throttle traffic on congestion
Socket
Server
// create a socket object
int socket(int domain, int type, int protocol);
// bind socket to IP address
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
struct sockaddr { sa_family_t sa_family; char sa_data[14]; }
// tell OS to prepare for incomign requests, buffer to backlog
int listen(int sockfd, int backlog);
// accept connection, return new socket with connection peer info
int accept(int sockfd, struct sockaddr *restrict addr, socklen_t *restrict addrlen);
Then do read(), write() on the socket
Treated as a special *inode to integrate with VFS
Transfer
Sliding window, with timeout
Congestion Control
Window size related to available BW
- Slow start (exponential)
- When timeout, reduce window size
- Additive growth, multiplicative drop
- Fast retransmit, fast recovery
Workflow
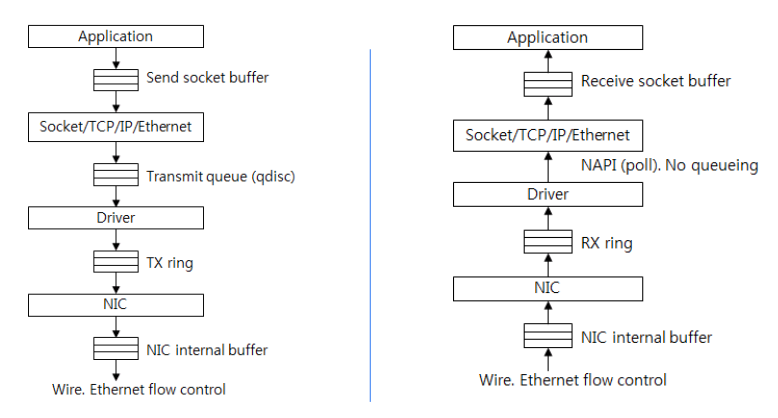 Need to limit usage, if specified through
Need to limit usage, if specified through cgroup
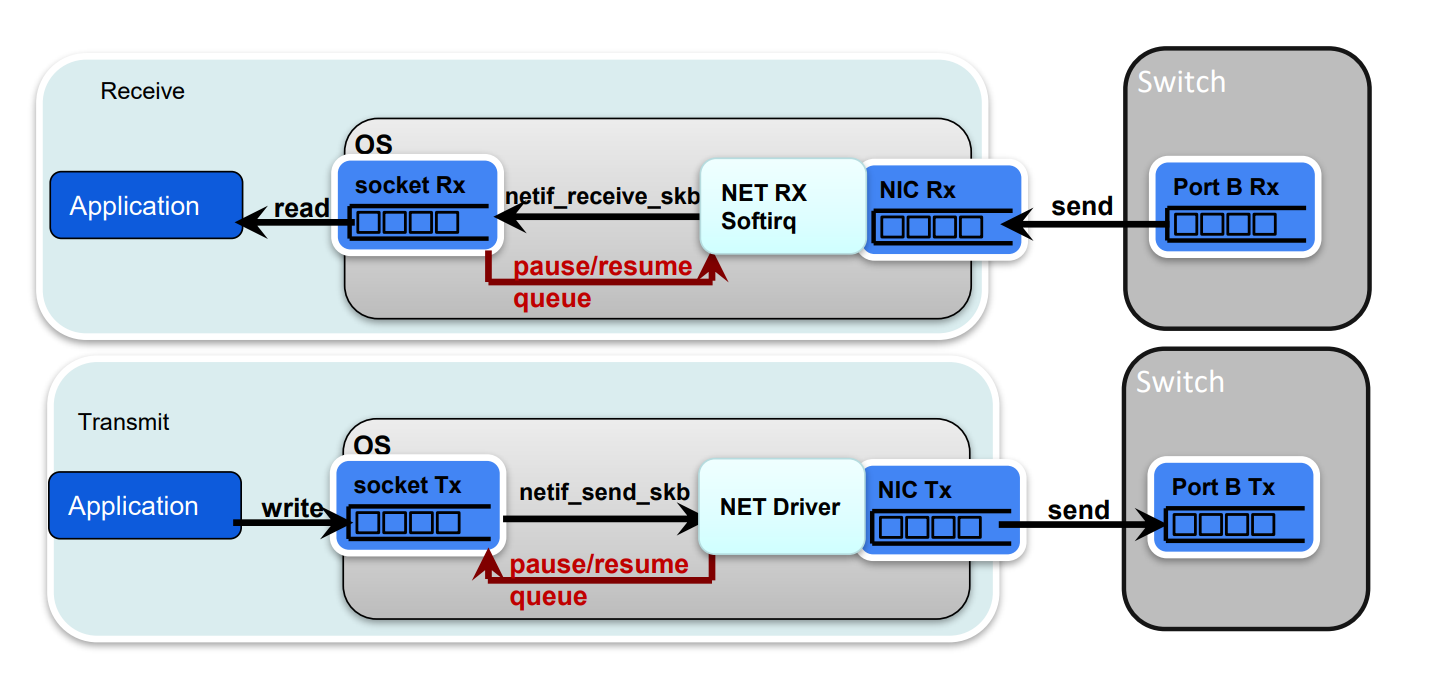 If OS buffer full, tell NET receive end to stop!
If OS buffer full, tell NET receive end to stop!
- If NET driver full, tell TCP to stop sending
TLS Security
Setup
key exchange, hashing function, etc.