
OS Notes: Memory Management
Published:
14. Memory Management and Hierarchy
Memory Hierarchy
The memory hierarchy is organized such that as you move down the layers, both capacity and access latency increase.
| Layer | Access Latency |
|---|---|
| Register | 0.2ns |
| Cache | 1-40ns |
| Main Memory | 80-140ns |
| CXL-Memory | 170-280ns |
| NVM | 300-400ns |
| Network Attached Memory | 2-4μs |
| SSD | 10-40μs |
| HDD | 3-10ms |
Chip Evolution: Clock speeds plateaued around 2006.
- Core Prioritization: There has been a shift to prioritizing using more cores.
- From an OS perspective, systems need to be scalable to handle this multi-core shift. The Memory Wall: Increasing CPU-DRAM gap
- Critical to focus on memory management.
OS Responsibilities
Basic Expectations
The OS has several fundamental responsibilities:
- Address Mapping: physical – virtual
- Rapid Switching: Keeping multiple applications in memory for quick context switching.
- Protection: Maintaining a protection scheme between processes.
- Parallelism: Supporting high parallelism for systems with $O(10)$ cores.
Core Management Goals:
- Sharing: Allowing multiple processes to occupy memory simultaneously.
- Transparency: Hiding the physical memory details from the process.
- Protection: Isolating processes from one another.
- Efficiency: Managing memory as one of the scarcest resources while maintaining performance.
Early Management Techniques
Base and Limit Registers
Two hardware registers: Base and Limit.
- Base: The start address of a program in physical memory.
- Limit: The total length of the program.
- Hardware Setup: When a process starts, it sets the base register in hardware.
- Context Switching: During a switch, the Kernel changes the base register to that specific process’s base.
Address Space Swapping
If OOM, some programs are swapped out to the disk.
- Problem: introduces “holes” in memory.
- Solution: Rearranging memory using the base register (memory compaction).
- High latency
- If a process needs more memory, may need to be reallocated
Fragmentation
Internal Fragmentation
- Definition: Space within an allocated chunk of memory goes unused.
- Solution: Allocate memory in smaller chunks.
- Higher bookkeeping costs
External Fragmentation
- Definition: Free space exists, but it is not contiguous, preventing large allocations
- Solution: Defragmentation to make free chunks contiguous.
- Extensive data movement
Allocation Strategies
- Best fit: Choose the smallest block available
- Small pieces of external fragmentation (unusable)
- Worst fit: Finds the largest chunk to ensure big chunks remain available.
- Larger external fragmentation (less of a problem)
- First fit: Allocates the first chunk that fits, fast
- Next fit: Searches for the first chunk that fits, starting after previous allocation.
Buddy Allocator
- Logic: Only considers blocks of memory in powers of 2 (\(2^N\)).
- Splitting: If a block size isn’t available, higher blocks are broken into smaller ones.
- Speed: Uses a bitmap and size data for cheap and fast jumps.
- Merging: Called “buddy” because you merge with your buddy to the left or right.
- Drawback: Significant internal fragmentation (e.g., a 129-byte request takes a 256-byte block).
Virtual Address
CPU -> MMU -> Physical memory
Can’t map contiguously. Space between stack and heap too huge
Segmentation
Maps each region (segment) to memory independently.
- Each segment has an associated base address and size.
- Errors: Invalid access results in a Segmentation Fault.
Problems:
- Causes external fragmentation
- Fine-grain sharing impossible
- Segment collision risk
Paging
Divide virtual and physical memory into fixed-sized pages. 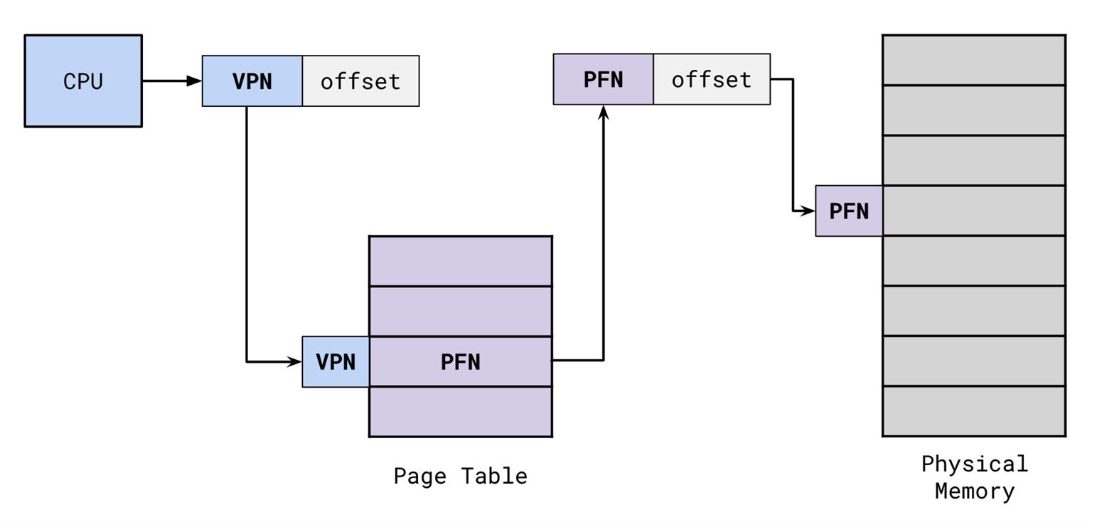 Virtual address divided into:
Virtual address divided into:
- Virtual Page Number (VPN)
- Page Offset (same for both VA and PA)
Translation Formula:
phys_addr = page_table[virt_addr/page_size] + virt_addr % page_size
E. 8-bit VA space, 10-bit PA space, 64-byte pages
Translate VA 241 to PAVPN | 0 | 1 | 2 | 3 | PPN | 2 | 5 | 1 | 8 |241 in VP 3, PP 8, PA =
8 x 64 + 49 = 561
Memory Tasks
Hardware has Page Table Base Register (PTBR) that points to base of page table
- Also managed by OS
- Updated with new base address on context switch
On page sharing, the page table of each process points to the same PFN on the physical memory
On Copy-on-Write (E. fork()), OS gives the child a copy of the parent’s page table
- On both tables, marked as read-only
- On Write, kernel copies child data onto a spare frame
Page Metadata
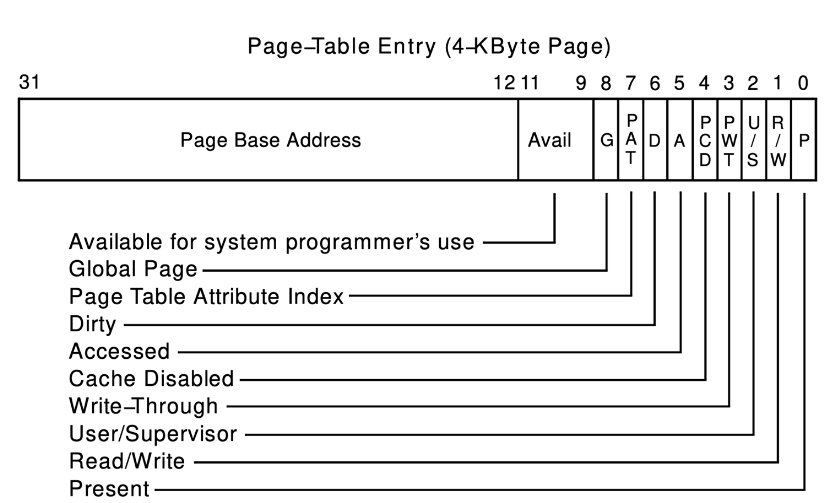
Metadata bits
p(present): if actively mapping to physical memoryw(writable), and readable, executableu(user): to protect kernel pages- Reference count, modified, caching disabled, etc.
15. Multi-Level Page Tables
Data now needs on e access for page tables
- Sparsity Problem: Simple page tables require massive allocations (around 1M entries) that are mostly empty.
- 2-Level Solution: Uses a Page Global Directory (PGD) and individual Page Tables.
- Allocation: Only allocate the page tables that are actually in use.
E. 32-bit VA, 4KB page size, page table entry size 4B
2^32 / 2^12 = 1M virtual pages (1M PT entries) per process
- Most unused!
Need only allocate page table that we need
- Divide 1M page tables into 1K x 1K
- If some entries unused, no need to allocate!
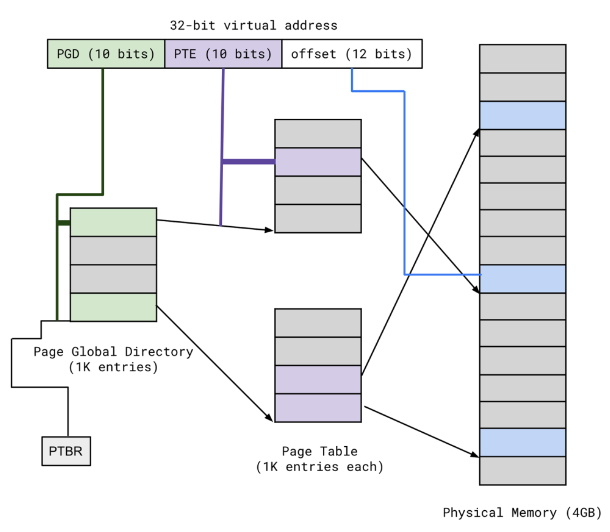
PTE_base = [PGD_base + PGD_index]
Frame_base = [PTE_base + PTE_index]
Physical_addr = Frame_base + offset
- More levels for bigger memory
- Problem: may hurt locality
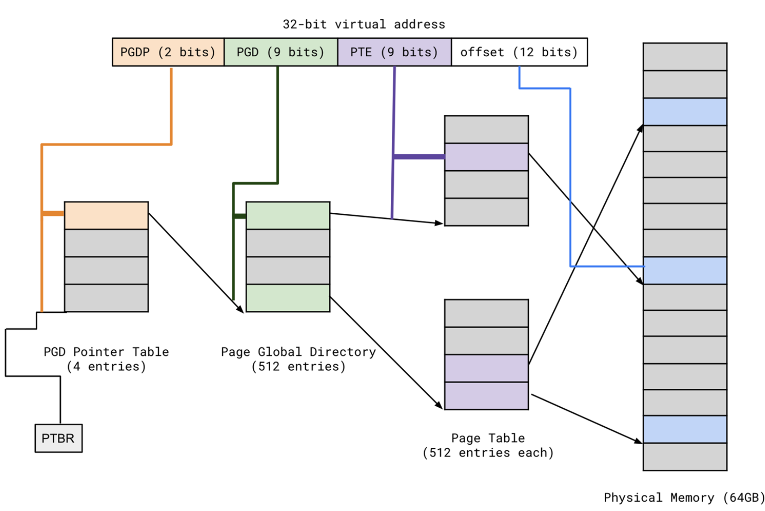
- Dereference table pointer (VA) to get the table base (PA)
- Translate table base PA back to VA
- + offset
Inverted Page Table
Page table entry for every physical page
Translation Lookaside Buffer (TLB)
A cache that immediately returns the Page Frame Number (PFN) if the VPN is inside.
- Small
- Support fast parallel search
- Temporal locality
- Some have second level TLB
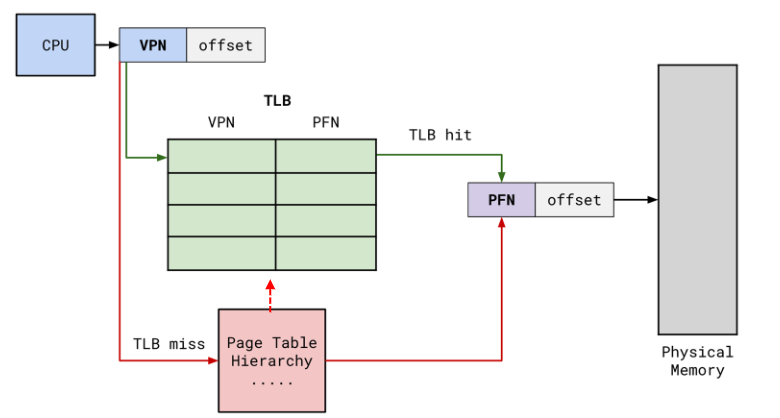
Context Switching
- Flush entire TLB
load cr3
- Attach ID to TLB entries
- Address space identifier (ASID)
16. Virtual Memory Management
20% memory gets 80% access
- Swap the 80% in disk
- Turn off the present bit (inactive PA mapping)
- OS remembers disk address
Page Fault
If page is not present (p = 0)
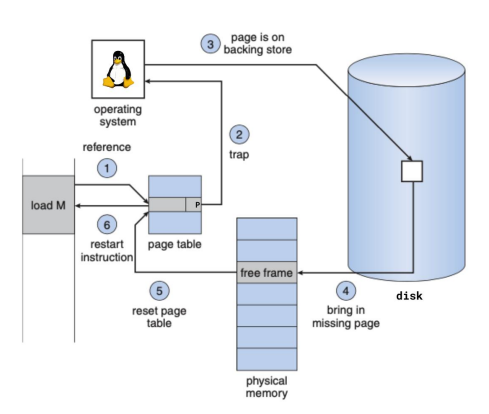
loadinstruction from MMU checks TLB, TLB miss, check page tablepresent = 0, trap into OS via page fault- OS issue IO request and put process to sleep
- May need to swap pages out to make space
- Why
kmalloc()would block when finding new space
- IO done, page written to free frame of physical memory
- Update PTE to the new Physical Frame Number (PFN), set
present = 1 - Restart
loadinstruction- TLB miss, but page walk would succeed
Also handles illegal access
- Send process
SIGSEGV - or handle COW
Restarting Instructions
HW must allow resuming after fault
Also must provide kernel with information about the fault
- Faulting VA
- Address of faulting instruction
- Access type (R/W/instruction fetch?)
Idempotent instructions are easy to restart
- Just re-execute
- E. load/store
Complex instructions are hard
- E. string move, need to adjust registers to resume
Fetching
Need to fetch the page that caused the fault
- Also prefetch surrounding pages
- Overlap IO overhead
- Also pre-zero unused zero pages
- For stack, heap, global memory, anonymous
mmap - For security
- For stack, heap, global memory, anonymous
Victim Strategies
Make reasonable decision at reasonable overhead
1. Optimal Page Replacement
Swap out pages that won’t be used for longest time in the future
- Hard to accurately predict!
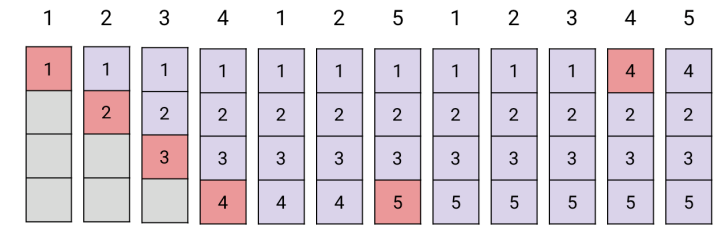
- In God’s eye,
4is farthest away in the future, so evicted - First 4 faults are compulsory
2. FIFO
Swap out pages that are loaded first
- Fair
Belady’s anomaly: FIFO fault rate may increase as memory increases ?!
3. Least-Recently-Used (LRU)
Takes advantage of locality
Implementation
- Hardware time counter for each page
- Each reference, save system clock
- Replacement: linear scan for the oldest
- Software: doubly linked list of pages
- Each reference moves to front of list
- Replace the back
- \(O(1)\), but need several pointer updates
- High contention on multiprocessor
LRU Approximation: Clock Hand Algorithm
- Imagine physical frames are arranged in a large circle
- Find a victim not recently accessed, but not necessarily the LRU
- Maintain a reference bit per page
- On reference,
ref = 1 - OS maintains a pointer (clock hand) on where it last stopped
- When a page needs to be evicted
- If
ref = 1, setref = 0and go on - If
ref = 0, evict this page, since not touched for “a while”
- If
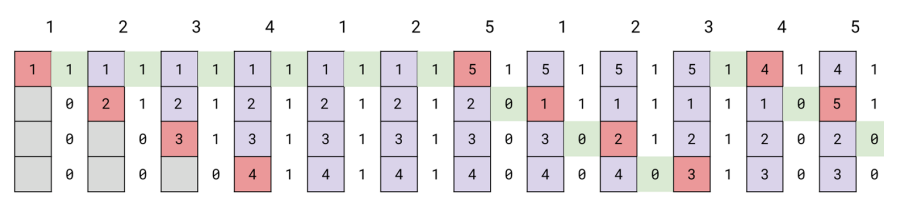
- When
5is inserted, everyone is on, and the resets.1evicted in the second iteration
Add a second clock hand (pointer) for large memories
- Proactively clears
refbit - Reduce eviction interval
Clock Hand with Dirty Pages
Dirty page: modified content
- Dirty pages are more expensive to evict, disk writing is expensive
Clock extension: use dirty bit to prevent evicting dirty pages
- Same as above, but skip if
dirty = 1 - If no victim found, run swap daemon to flush unreferenced dirty pages
4. Random
Works surprisingly well, since avoids worst case
Page Buffering
Page fault costly: need 2 disk IOs per fault (swap out victim, swap desired page in)
Idea: reduce number of IOs on critical path
- Keep pool of free page grams
- On fault, immediately use free page
- Can resume without writing out victim
- Add victim page to free pool
- Can also copy pages back to free pool
- Recycle
Page Allocation
Global: no “ownership” of memory
- E. LRU: evict page from any process
- Risk of memory hog
Local: isolated
- Each process has memory limit
Thrashing
Process require more memory (working set size) than system has
- Too frequent swap
- Limited by disk speed :(
Why happens
- No temporal locality in access patterns
- Hot memory larger than RAM
- Too many processes
- Multiprogramming
Solution
- Working set: Only run processes with memory requirements that can be satisfied
- Put rest to sleep
- Page fault frequency: adjust memory for each proc
- PFF = page fault / instruction executed
- If PFF too high, processes need more memory
- If OOM, switch process out
- If PFF low, memory can be taken away
Predict Working Set
All pages that processes will access in next \(T\) time
- Approximate with past \(T\)
Periodically scan all resident pages
ref = 1: clear idle timeref = 0: add CPU consumed since last time
Two-Level Scheduler
Process Activity
- Inactive: working set intentionally not loaded
Balance set: union of all active working set
- Must be smaller than physical memory
- Move process from active to inactive, until balance set is small enough
- Periodically activate
- Update balance set as working set changes
Parameters
- T
- Picking processes for active set
- Counting shared memory
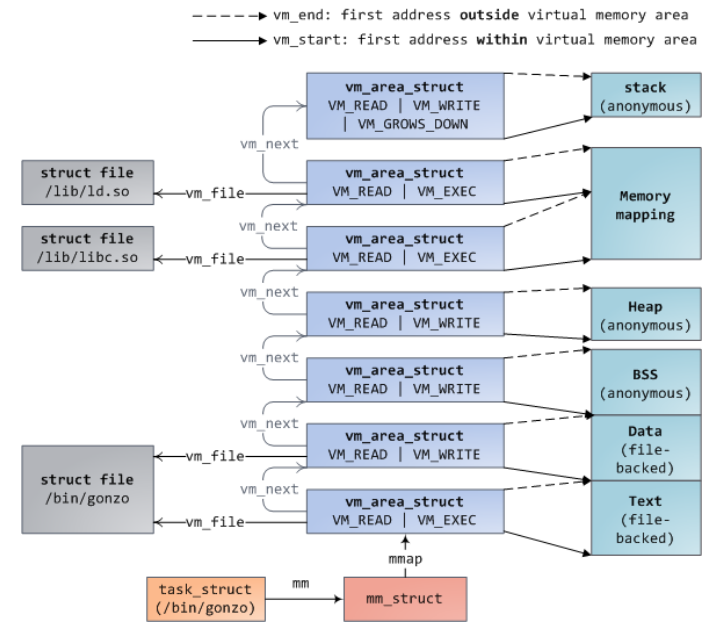
17. Linux Memory Management
Check mappings:
cat /proc/<pid>/maps
Virtual Address Space
struct mm_struct {
struct vm_area_struct *mmap;
struct rb_root mm_rb; // red black tree
pgd_t *pgd; // Page Global Entry
// ...
unsigned long start_code, end_code, start_data; // ... fundamental areas
};
Typically per process
- Contains pointers to
vm_area_structs pgd: HW 6
struct vm_area_struct {
unsigned long vm_start, vm_end; // address range (start, end+1)
struct vm_area_struct *vm_next, *vm_prev; // linear list
struct rb_node vm_rb;
struct mm_struct *vm_mm; // parent
pgprot_t vm_page_prot;
unsigned long vm_flags; // premissions
struct file *vm_file // optional file backing
unsigned long vm_pgoff; // offset within vm_file
struct list_head anon_vma_chain; // anonymous mappings with locking
struct anon_vma *anon_vma;
const struct vm_operations_struct *vm_ops // functions to opeaate on them
vm_fault_t (*fault) (struct vm_fault *vmf); // fault handler
};
- Linear traversal via linked list
mmap(useful for proc maps) - Log traversal via
mm_rb(quickly find an area for a givenvaddr) - Data use
unionto save space
Page Fault
Need to trace, some deterministic decisions
do_page_fault() // Exception handler for page fault
\_ find_vma() // rbtree traversal to find VMA holding faulting address
\_ handle_mm_fault() ->__handle_mm_fault() -> handle_pte_fault()
\_ do_fault()
\_ do_cow_fault() // e.g. You can tell if a page is marked for COW
// when the PTE is write protected but the VMA isn't.
\_ do_read_fault()
\_ do_shared_fault()
-> __do_fault() called by the above three handlers
\_ vma->vm_ops->fault()
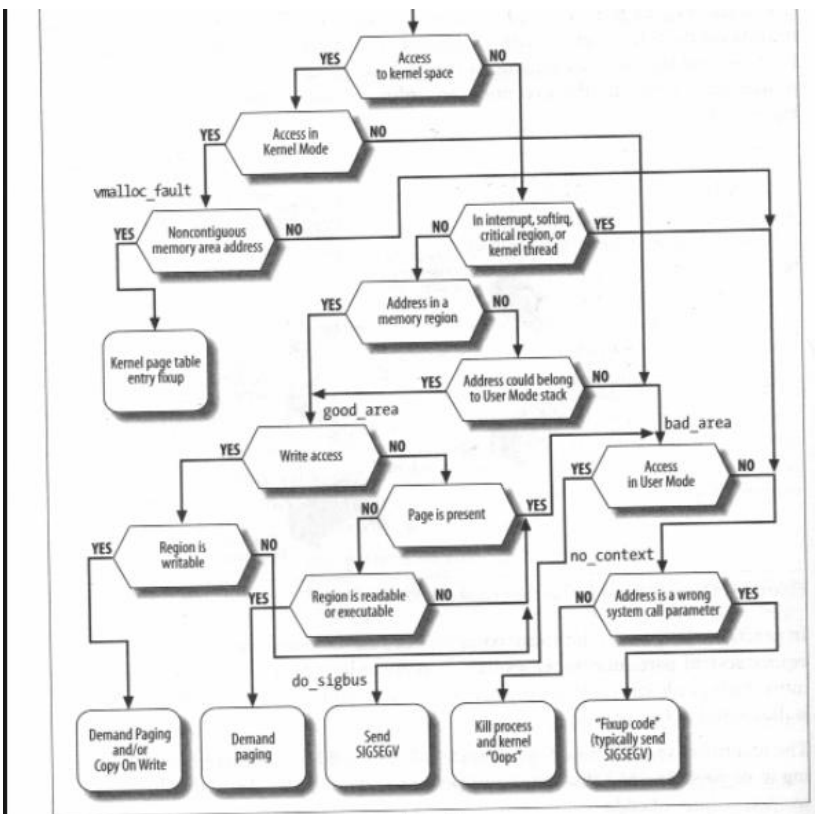 For error:
For error:
- If user process, kill
- If kernel process, bad, especially if in critical section
mmap() tracing
SYSCALL_DEFINE6(mmap_pgoff)
\_ ksys_mmap_pgoff()
\_ vm_mmap_pgoff()
\_ mmap_region()
- As VMA created, kernel tries to coalesce adjacent VMAs, with same backing/permissions
highmem
32-bit system only has 4GB VA. Make top 1GB instant, direct mapping (
highmem)
kmalloc()always has linear mapping
Kernel reserves 1GB VA with “arbitrary” mappings
- Linear: directly map kernel VA->PA
- For performance, avoid page walk
- Indirect: map anything to it
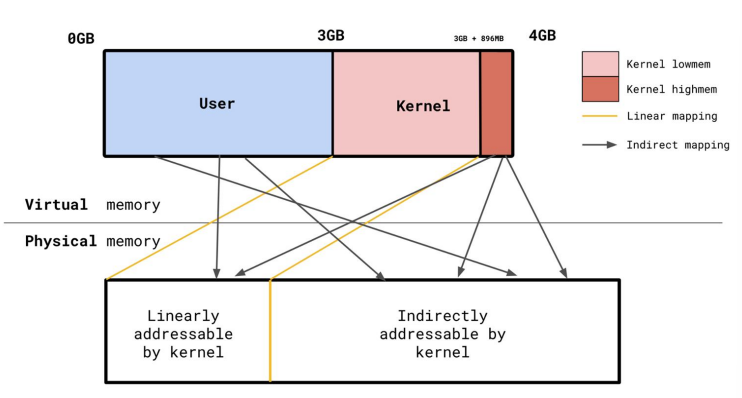
- User: 3GB
- Kernel
lowmem: 896MB permanent map, direct - Kernel
highmem: beyond 896MB, similar indirect as user space
Physical Reverse Mapping
struct page, for every physical page
Houses metadata regarding to physical frame
- Easy for contiguous memory space
- Global array of
struct page *, aligned with physical frames - Given PFN, can derive physical frame
struct page {
atomic_t _refcount; // can decallocate if 0
struct list_head lru;
struct address_space *mapping; // reverse mapping
pgoff_t index; // offset within mapping
void *virtual; // kernel virtual address
}
Linux Page Cache
Uses file-backed
mmap
- Most files go through page cache
- Integrate IO caching and mmaped files
- Indexed by
<inode, vpageofs>- If miss, frame allocated and IO issued as a set of block IOs
- Responsible for synching and writebacks
struct vma has the open file backing pointer:
struct file *vm_file; // optional file backing
Referred in struct file
struct address_space *i_mapping;
Serving read() and write()
Reading
- Go to page cache, see if it’s there
- If not, allocate the page, fill from disk, and cache into
address_space
Writing
- Make page dirty in the cache
- Write-back cache: Eventually written back asynchronously or by user
sync() - Write-through cache: write back immediately to disk
- Write-back cache: Eventually written back asynchronously or by user
Serving mmap()
Each mmap() call creates or extends a single VMA, linked to task’s mm_struct
- Can be anonymous or file-backed
MAP_SHARED Also connected to page cache
- After new VMA created, file contents eventually faulted into memory
- Pages installed to page tables
MAP_PRIVATE (private overwrite)
- CoW
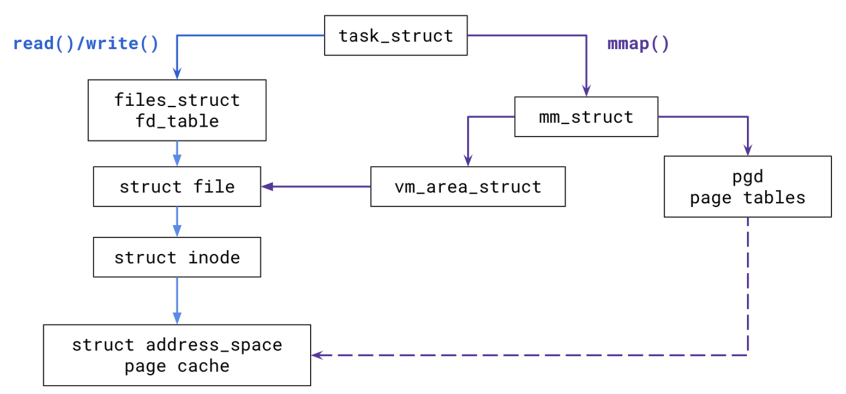
- Every IO eventually kept into page cache
Replacement Policy
Some approximation of LRU, live in main RAM
- Bad for a huge, rarely used file. Will evict a lot of cache!
Two LRU lists: active and inactive that partitions the RAM
New page needs to “prove” its activity
- Divide page into E. 1/3
active; 2/3active
Creation
- First load: head of
inactive - Evict tail of
inactivePromotion/demotion - Access inactive: minor fault; promote to
activehead activefull: demote tail toinactivehead
OOM Killer
Handled in mm/oom_kill.c
- Select a process for killing
static void select_bad_process(struct oom_control *oc); - Select from heuristics
long oom_badness(struct task_struct *p, unsigned long totalpages); - Send
SIGKILL- Not given a warning :(
Alternatives
Intervenes before OOM killer
- Daemon monitors (E.
systemd-oomd) - Memory limit with
cgroups
HW 6
Part 1
static long farfetch(unsigned int cmd, void __user *addr, pid_t target_pid,
unsigned long target_addr, size_t len)
- Find
pid_struct,task_struct, andmm_structoftarget_pidstruct pid *pid_struct = find_get_pid(target_pid); struct task_struct *tsk = get_pid_task(pid_struct, PIDTYPE_PID); struct mm_struct *mm = get_task_mm(tsk); struct page **pages = kmalloc_array(page_count, /*...*/); // ... kfree(pages); mmput(mm); - Perform page walk
mmap_read_lock_killable(mm); pgd_t *pgd = pgd_offset(mm, target_addr); p4d_t *p4d = p4d_offset(pgd, target_addr); pud_t *pud = pud_offset(p4d, target_addr); pmd_t *pmd = pmd_offset(pud, target_addr); pte_t *ptep = pte_offset_kernel(pmd, target_addr); pte_t pte = *ptep; pte_unmap(ptep); // ... mmap_read_unlock(mm); - Do the work
Just one page: get
struct pagepage *page = pte_page(pte); get_page(page); // ... put_page(page);pte_page()converts the PFN tostruct page*get_page()increments_refcount, pinning the physical page
case FAR_READ: copy_to_user(addr, kmap_local_page(page) + page_off, len) kunmap_local(page); break; case FAR_WRITE: copy_from_user(kmap_local_page(page) + page_off, addr, len) set_page_dirty_lock(page); kunmap_local(page);kmap_local_pagemaps kernel address space to the physicalpte_page(pte)
Part 3
Directly copy
struct page[] pagesgivenmmandtarget_addr
Replace page walk with:
pages = kmalloc_array(page_count, sizeof(struct page *), GFP_KERNEL);
get_user_pages_remote(mm, target_addr, page_count,
(cmd == FAR_WRITE ? FOLL_WRITE : 0) | FOLL_FORCE,
pages, &locked);
- Perform page walk
- Pin pages (
get_page) for every page it finds- If page missing, trigger page faults - Flags:
FOLL_WRITE: perform CoW;FOLL_FORCE: override permissions
- If page missing, trigger page faults - Flags:
Then preform copy for each page in pages
Size to copy
- Begin:
PAGE_SIZE - page_off - Middle:
PAGE_SIZE - page_off, wherepage_offreset to 0 - End:
len - (user_page_addr - addr), whereuser_page_addrincremented