
OS Notes: Scheduling
Published:
12. Scheduling
How synchronization works
- Dispatcher: Low-level mechanism
- Responsible for context switch (
context_switch())
- Responsible for context switch (
- Scheduler: High-level policy
- Decide which process to run:
pick_next_tesk()
- Decide which process to run:
Metric
- Min waiting tie
- Max CPU util
- Max throughput
- As many processes as possible per unit time
- For batch jobs
- Min response time
- Fairness
Policies
1. FIFO
- Non-preemptive (you can run as long as you want)
- Implementation: FIFO queue
Good:
- Simple
- Fair
Bad:
- Waiting time depends on arrival order
- Short process stuck waiting (Convoy effect)
2. Short Job First (SJF)
without preemption
- On the waiting queue, run shortest job first
3. Shortest Remaining Time First (SRTF)
- If a process arrives with shorter time than the remaining current process time, schedule new process
- aka SJF with preemption
Good:
- Reduces average waiting time
- Proven to be optimal!
Bad:
- Starves long jobs
- Avoid starving: prioritize processes with long wait time
- Not practical to predict burst time
- Use past to predict future
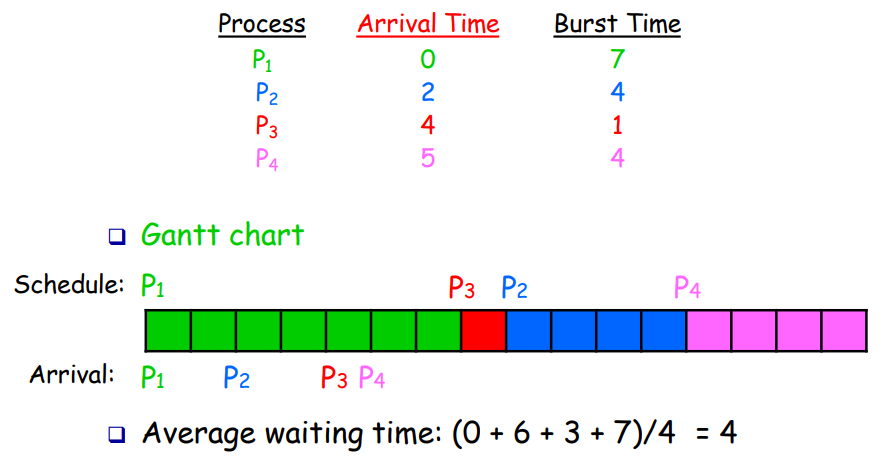
4. Round Robin (RR)
- aka preemptive FIFO
- Each process runs a predetermined time slide, then preempt and move back to queue
- Need optimal time slice ((wait time > response time) vs # context switch)
Good:
- Low response time, fair allocation,
- Low average waiting time
- Even when job lengths vary widely
Bad:
- Poor average waiting time when jobs have similar lengths
- Performance depends on time slice length
Priorities
Associated with each process (“niceness”)
- Run highest-priority process that’s ready
- Round-robin among equal priority
- Can be statically assigned
- Also dynamically changed by OS
- Aging for long queuing process
for (pp = proc; pp < proc+NPROC; pp++) {
if (pp->prio != MAX)
pp->prio++;
if (pp->prio > curproc->prio)
reschedule();
}
Priority Inversion
If a high-priority process depends on low priority process (E. to release a lock)
- When a medium-priority process runs
- High-p process wastes CPU cycles
- Med-p process has high effective priority -> priority inversion
Solution: (Temporarily) inherit the priority of waiting process
- Inheritance chain
- Reset
Multi-Level Feedback Queue (MFQ)
Queues with different priority levels
- Process priority changes based on observed behavior
Parameters
- Number of queues (140 in Linux)
- Scheduling algorithm for each queue
- When to upgrade/demote a process
- Default queue a process will start in
Rules
- If
p(A) > p(B), A runs - If
p(A) = p(B), A and B runs in RR using the time slice of the queue - When a job enters the system, starts in highest priority queue
- Once a job uses its allocated time at a level, priority reduced
- After some time period, move all jobs to the highest priority queue
Kernel Representation
nice command, [-20, +19], lower more priority
- Mapped to 100-139 in kernel
- 0-99 are reserved for real time processes
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
#define MAX_PRIO (MAX_RT_PRIO + 40)
#define DEFAULT_PRIO (MAX_RT_PRIO + 20)
#define NICE_TO_PRIO(nice) (MAX_RT_PRIO + (nice) + 20)
#define PRIO_TO_NICE(prio) ((prio) - MAX_RT_PRIO - 20)
#define TASK_NICE(p) PRIO_TO_NICE((p)->static_prio)
Computation
prio, normla_prio, static_prio
Dynamic prio is simply a booster if RT priority
- If not RT boost restore it to normal priority
- E. holding lock
p->prio = efffective_prio(p);
static int effective_prio(struct task_struct *p) {
p->normal_prio = normal_prio(p);
if (!rt_prio(p->prio))
return p->normal_prio;
return p->prio;
}
static inline int normal_prio(struct task_struct *p) {
int prio;
if (task_has_rt_policy(p))
prio = MAX_RT_PRIO-1 - p->rt_priority;
else
prio = __normal_prio(p);
return prio;
}
static inline int __normal_prio(struct task_struct *p)
return p->static_prio;
- For RT, since higher
rt_priorityis more important, need subtraction - For regular, just return static priority

static_prio: base priority, purely from nice values for normal tasksnormal_prio: priority “entitled” based on scheduling policy- Same as
static_priofor non-RT - Higher for RT tasks
- Same as
prio: effective priority, used by scheduler right now- Can be boosted
Load Weights
struct load_weight {
unsigned long weight, inv_weight; // inv for division
};
Idea: process one nice level down gets 10% more CPU power
- Kernel converts priority to weights
- Nice level -> priority -> weights (
prio_to_weight[40]) SCHED_IDLEtasks will get a very small weight (like 2)
static void set_load_weight(struct task_struct *p) {
// RT: global load balancing
if (task_has_rt_policy(p)) {
p->se.load.weight = prio_to_weight[0] * 2;
p->se.load.inv_weight = prio_to_wmult[0] >> 1;
return;
}
if (p->policy == SCHED_IDLE) {
p->se.load.weight = WEIGHT_IDLEPRIO;
p->se.load.inv_weight = WMULT_IDLEPRIO;
return;
}
// load the acutal weight
p->se.load.weight = prio_to_weight[p->static_prio - MAX_RT_PRIO];
p->se.load.inv_weight = prio_to_wmult[p->static_prio - MAX_RT_PRIO];
}
- For RT tasks, fill a very high
prio_to_weight- Not actually used, tells scheduler that this CPU is very busy
Modify Weights
Modify struct load_weight
static inline void update_load_add(struct load_weight *lw, unsigned long inc)
lw->weight += inc;
static inline void inc_load(struct rq *rq, const struct task_struct *p)
update_load_add(&rq->load, p->se.load.weight);
static void inc_nr_running(struct task_struct *p, struct rq *rq)
rq->nr_running++; inc_load(rq, p);
- Doesn’t calculate
inv_weightfor simplicity (avoids division) - Only
.weightis needed for load balancing and calculating time slices .invweightused to calculatevruntime
Multicore
Setup: Symmetric Multiprocessing (SMP)
- Identical CPU
- Same access time to main memory
- Private cache
1. Global Queue of Processes
- Good CPU util. Fair to all processes
- Global queue lock (not scalable). Poor cache locality
2. Dispatcher Core
Dispatcher core handles the scheduling and synchronization
- Bad: one fewer core
3. Per-CPU Queue
Static partition to individual CPUs
- Simple, scalable, cache locality
- Load-imbalance, unfair. Lower CPU util
4. Hybrid Approaches
Modern OS
- Global and per-CPU queues
- Migrate processes across per-CPU queues
- Cache recent processes on the same CPU
13. Linux Scheduler
1. \(O(N)\)
Scan the entire list of runnable processes to select
- Global RQ
- More contention for multicore
- Preemptive time slicing: jiffies
- Slices: when blocked before slice ends, half of the remaining slide is added to the next epoch
- ana. increase in priority
2. \(O(1)\)
Policies
- Real-time policies
SCHED_DEADLINEuses Global Earliest Deadline First (GEDF)SCHED_FIFO, until finish, or preempted by a higher prioritySCHED_RRderived fromSCHED_FIFO, but with RR
- Non-real time policies
SCHED_NORMAL(CFS) based on nice valueSCHED_BATCHderived fromSCHED_OTHERto optimize throughputSCHED_IDLEderived fromSCHED_OTHER, but with nice values lower than 19
Implementation
- 2 Independent RQ for each CPU
activeandexpiredarray- Each is an array of RQs
- Task are in array, indexed according to priority
- Real time: assigned static priorities
- Nice values: dynamic priorities
- \(\pm 5\) range
- More interactive tasks will be blocked longer
- Decay when quantum used up
- Timer count drops to -1
- Immediate reset, recalculate priority, and put into higher queue
- Over time,
activearray empty out toexpired - When
activecompletely empty, exchange
Need to find the highest priority queue that is not empty
ffz()find first zero- Only examines fixed-size bitmaps of queue states
dequeue_front()
3. CFS
Maintain fairness and balance
- Balance timer
- Determine virtual runtime
Use dynamic time slice on EPOCH definition
EPOCHcontrolled viasched_latency(E. 48 ms)- Each task in a RQ gets an equal share of `EPOCH
- Can configure
min_grannularity(E. 6 ms) Runtime then weighed based on nice value, with a map
- Can configure
vruntimenormalizes actualruntimebased on priority- CPU “debt account”
- Smallest
vruntimeis selected, sorted by RBT
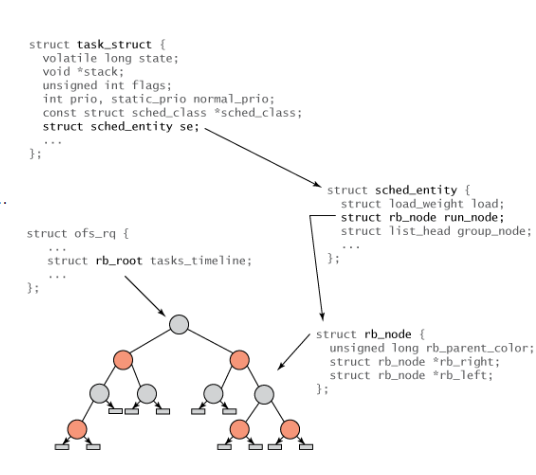
Data Structures
Extract task with minimum
vruntime
Time-order RB tree
- Operations \(O(\log n)\)
- High need at lower-left, pick the leftmost
Scheduling Class
If someone spawns a lot of threads, Need to group for fairness
procinterface
sched_class provides a common set of functions that define scheduler behavior
- ana. CPP
vtable
Load Balancing
Scheduling domains allow grouping processors for load balancing/segregation
- Processors can share, or independent
Goal: equalize load across all cores
While maximizing locality
- E. Sleeping tasks will be put on a single core
- When idle, steal other people’s work
- Locality: steal close cores
- Hierarchical balancing
- Locality: steal close cores
- When busy, push tasks out for others
Maintain a load average and history to determine stability Neighbor check
- Level in hierarchy: cost to migrate
- Make small changes by pulling from other CPU
- Ensure upper hierarchies are balanced (less frequently checked)
- Load calculated by the leftmost node
4. EEVDF
Earliest Eligible Virtual Deadline First
Address CFS issues:
- Lack of latency guarantee
- Sleeper fairness
- Too much heuristics/tuning
Lag: difference between idea and actual
Time slice = base time slice / weight Deadline = vruntime + time slice + lag
HW 4
Slab Allocator
- Free list: block of available, already allocated data structures (object cache)
- Problem: no global control Slab layer: generic data-structure caching layer
- Cache frequently used data structures
- One cache per object type
kmalloc()built on top of it
States of slabs
- Full: all allocated
- Empty: none allocated
- If no empty slab, one is created
- Partial: some allocated, satisfies kernel request first
HW 5 Scheduler
HW Tips
Per-CPU kthreads: some tasks can only run on a specified CPU
- May be very bad!!
Use Version 6.8!
Pay attention to locking!
Debugging
First make the number of CPUs to 1 Then slowly add things, and slowly take debugging flags out
- Check if locks grabbed? If locks not grabbed?
https://columbia-os.github.io/dev-guides/kernel-debugging.html
KConfig
DEBUG_INFOKALLSYMSDEBUG_BUGVERBOSEPRINTK_CALLER: for multithreaded debugging
Logging
- Print
KERN_ERRandKERN_DEBUG - Seen by
sudo demsg
Serial Console
- Redirect messages to a file on host machine via virtual serial port
- Need edit boot parameters
BUG_ON
kernel/sched/core.c
BUG_ONcrashes earlier thandmesg
- Specify the assumptions (
assert) panic()function to print info, instead ofBUG_ON
Data Structures
task_struct
struct task_struct {
...
int prio, static_prio, normal_prio;
unsigned int rt_priority;
struct list_head run_list;
const struct sched_class *sched_class;
struct sched_entity se;
unsigned int policy;
cpumask_t cpus_allowed;
unsigned int time_slice;
...
};
- Priorities
static_prio: static, assigned when started- Can only be modified by
nicesched_setscheduler
- Can only be modified by
normal_prio: dynamic computed from static and scheduling policy- Inherited with
fork()
- Inherited with
prioconsidered by the scheduler- When kernel needs to boost (very temporary change)
rt_priority: real time process- 0 lowest, 99 highest (differ from nice values)
sched_class- Scheduler can also schedule groups (instance of
sched_entity)
- Scheduler can also schedule groups (instance of
- Data
policySCHED_NROMALhandled by completely fair schedulerSCHED_BATCH,SCHED_IDLE: completely fair, but less importantSCHED_RR,SCHED_FIFO: real-time scheduler class!
run_list: list head by RR schedulertime_slice: remaining time quantum
Run Queue
Per CPU. Each active process only on one run queue
static DEFINE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
struct rq {
unsigned long nr_running;
#define CPU_LOAD_IDX_MAX 5
unsigned long cpu_load[CPU_LOAD_IDX_MAX];
struct load_weight load;
struct cfs_rq cfs;
struct rt_rq rt;
struct task_struct *curr, *idle
;
u64 clock;
};
nr_running: process number on the queuecpu_loadtracks past load behaviorloadis a measure of current load on RQ (weighted)cfs,rt: sub RQ for fair and RT schduler- Holds the actual queue!
curr: current runningtask_structidle:task_structcalled when no other runnable process is availableclockupdated each time periodic scheduler calledupdate_rq_clock()
Scheduler Class
Connect generic & individual scheduler
Function pointers in special structure
- Need to set a few function pointers
struct sched_class {
const struct sched_class *next;
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int wakeup);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int sleep);
void (*yield_task) (struct rq *rq);
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p);
struct task_struct * (*pick_next_task) (struct rq *rq);
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
void (*set_curr_task) (struct rq *rq);
void (*task_tick) (struct rq *rq, struct task_struct *p);
void (*task_new) (struct rq *rq, struct task_struct *p);
};
Hierarchy
schedule() searches from top to bottom
- Real-time processes
- Completely fair
- Idle task
Example
Task DB_QUERY sleeping for a network packet
select_task_rqmigrate_task_rqenqueue_taskonto RQcheck_wakeup_preempt: is a task currently running?- Is it more important than me?
- If not, kick it off (raise a reschedule flag)
pcik_next_task:DB_QUERYset_next_task: update CPU register- If swapping CPUs
set_cpus_allowed: sets the task to not allowed to run on current core put_prev_task: cleanup- Now CPU idle, call
balancefor tasks- If so, pull tasks here
context_switch: actual hardware switch, move cur process to new CPUyield_taskordequeue_taskwhen giving up neededtask_dead: cleanup function
Macros:
#define cpu_rq(cpu) (&per_cpu(runqueues, (cpu)))
#define this_rq() (&__get_cpu_var(runqueues))
#define task_rq(p) cpu_rq(task_cpu(p))
#define cpu_curr(cpu) (cpu_rq(cpu)->curr)
Core Implementation
Periodic Scheduler
Function called by the kernel with frequency HZ Tasks
- Manage kernel scheduling stats (incrementing counters)
- Activate periodic scheduling method of the schedule class for the current process
void scheduler_trick(void) {
int cpu = smp_processor_id();
struct rp *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
__update_rq_clock(rq)
update_cpu_load(rq);
if (curr != rq->idle)
curr->sched_class->task_tick(rq, curr);
}
__update_rq_clock()advances time stamp of currentstruct rq- Hardware clock interface
update_cpu_load()updatescpu_load[]history (inserts at begin)
Main Scheduler: schedule()
Prefix __sched to decorate function that can potentially call schedule()
- Determine the current RQ and save the
task_struct *of the current active process toprev.- If the task yields, check if there is anything to run.
- If so, deactivate the task.
asmlinkage void __sched schedule(void) { struct task_struct *prev, *next; struct rq *rq; int cpu; need_resched: cpu = smp_processor_id(); rq = cpu_rq(cpu); prev = rq->curr; } Update the RQ clock and clear the reschedule flag of the current running task.
__update_rq_clock(rq); clear_tsk_need_resched(prev);- Delegate the work to the scheduling classes.
- If a task is trying to sleep but is willing to be woken up by a signal, make it running.
- Else,
deactivate_task()callssched_class->dequeue_task(), putting it to sleep.- Calls
p->sched_class->dequeue_task(rq, p). - I need to implement
dequeue_task().- Make sure this is done within a locked region.
- Calls
if ((prev->state & TASK_INTERRUPTIBLE) && signal_pending(prev)) prev->state = TASK_RUNNING; else deactivate_task(rq, prev, 1); put_prev_task()forces thesched_classto update stats and pick the next task.- If nothing is available, it runs the
idletask (low-power state).
prev->sched_class->put_prev_task(rq, prev); next = pick_next_task(rq, prev);- If nothing is available, it runs the
- If
pick_next_task()selects a new task, perform acontext_switch()at the hardware level.- This is architecture-specific.
- Save CPU registers and the stack pointer, load the next task, and change the address space.
if (prev != next) { rq->curr = next; // memory barrier here: make sure all previous operations complete context_switch(rq, prev, next); } - If no context switch is performed, execution resumes:
- If
TIF_NEED_RESCHEDis set, the scheduler found a better candidate; loop back.- Executes when the scheduler decides to stay with the current task, or has just switched back.
- Acts as the “exit gate” for the scheduling logic.
if (test_thread_flag(TIF_NEED_RESCHED)) goto need_resched; - If
Kernel Connections
I show some simple skeleton, boiler-plate code as a starting point
include/linux/sched.h
Internal kernel data structures
- Internal entity data structures:
struct sched_freezer_entity {
struct list_head list;
unsigned int time_slice;
unsigned short on_rq;
};
struct sched_heater_entity {
struct list_head list;
unsigned short on_rq;
};
- Add entries to
task_struct- This is carried for every task
struct task_struct {
// ...
struct sched_freezer_entity freezer;
struct sched_heater_entity heater;
// ...
};
include/uapi/linux/sched.h
Userspace API
- Anything userspace program needs to call
sched_setscheduler(),clone() - Exported to userspace
#define SCHED_FREEZER 7
#define SCHED_HEATER 8
Other Files
kernel/sched/freezer.c: actual scheduler implementationlinux/include/asm-generic/vmlinux.lds.h: kernel linker script
core.c
init task:
void __init sched_init(void) {
for_each_possible_cpu(i) {
struct rq *rq;
rq = cpu_rq(i);
// ...
init_freezer_rq(&rq->freezer);
init_heater_rq(&rq->heater);
}
}
Fork: called by every subsequent process after init
static void __sched_fork(unsigned long clone_flags, struct task_struct *p) {
INIT_LIST_HEAD(&p->freezer.list);
p->freezer.time_slice = FREEZER_TIMESLICE;
p->freezer.on_rq = 0;
/** init heater run_list **/
INIT_LIST_HEAD(&p->heater.list);
p->heater.on_rq = 0;
}
Freezer
Enqueue/Dequeue
Update fields of the queue and the sched entity!
static void enqueue_task_freezer(rq *rq, task_struct *p, int flags) {
struct freezer_rq *freezer_rq = &rq->freezer;
struct sched_freezer_entity *entity = &p->freezer;
list_add_tail(&entity->list, &freezer_rq->queue);
add_nr_running(rq); // adds global counter
freezer_rq->nr_running++;
entity->on_rq = 1;
}
list_del(&entity->list);
Pick/Put Task
Just pick the head of the freezer RQ
static struct task_struct *pick_next_task_freezer(rq *rq, ...) {
if (list_empty(&freezer_rq->queue))
return NULL;
struct sched_freezer_entity *entity = list_first_entry(&freezer_rq->queue,
struct sched_frezer_entity, list);
p = container_of(task, struct task_struct, freezer);
p->se.exec_start = rq_clock_task(rq); // allow sched to compute how long it runs
return p;
}
Typically called when yielding to another task
static void put_prev_task_freezer(rq *rq, task_struct *prev) {
update_curr_freezer(rq);
if (entity->on_rq) // entity = &prev->freezer
list_move_tail(&entity->list, &rq.freezer->queue);
}
Tick
If quantum expired, reset it
- If more than one needs to be rescheduled, preempt it
- Move it to tail
- Call
resched_curr()
static void task_tick_freezer(struct rq *rq, struct task_struct *curr, int queued) {
entity->time_slice--;
update_curr_freezer(rq);
if (entity->time_slice > LIMIT) {
entity->time_slice = LIMIT;
if (rq->freezer.nr_running > 1) {
list_move_tail(&entity->list, &rq->freezer.queue);
resched_curr(rq);
}
}
}
Update
- Compute
deltafromtask_struct.se.exec_startvoid update_curr_freezer(struct rq *rq) { task_struct *curr = rq->curr; if (curr->sched_class != &freezer_sched_class) return; int delta = rq_clock_task(rq) - curr->se.exec_start; - Update some stats
curr->se.sum_exec_runtime += delta; curr->se.exec_start = now; // ...
Yield
Just reset time-slice to 0. No need to handle special
Blocking Wait
- Task will set its state to
TASK_INTERRUPTIBLE - Adds itself to wait queue:
add_wait_queue() - Call
schedule(), which willdequeue_task_()
All end up calling
schedule()
Set Task
Called when picked, or switched to
freezer. Just set data structures
void set_next_task_freezer(rq *rq, task_struct *p, bool first) {
p->freezer.time_slice = LIMIT;
p->se.exec_start = rq_clock_task(rq);
}
Load Balancing
Can’t move if
- Pre-CPU kthreads
- Wrong affinity:
cpumask_test_cpu(dst_cpu, p->cpus_ptr) - Currently on CPU:
task_on_cpu(src_rq, p)
static task_struct pick_movable_task(rq *src_rq, int src_cpu, int dst_cpu) {
struct sched_freezer_entity *se;
list_for_each_entry(se, &rq->freezer.queue, list) {
struct task_struct *p = container_of(se, struct task_struct, freezer);
if (can_move_task(p, src_rq, src_cpu, dst_cpu))
return p;
}
}
static int idle_balance_freezer(struct rq *cur_rq, struct rq_flags *cur_rf)
- Find busiest CPU to pull task from
- Find first movable at busiest CPU
- Check if movable
- Perform migration
Heater
Entry only appears either in global rq or local
curr
struct heater_rq {
unsigned int nr_running; // global
struct list_head queue; // global
struct sched_heater_entity* curr;// local, not in freezer
};
struct sched_heater_entity {
struct list_head list;
unsigned short on_rq;
}; // no quantum
struct heater_rq global_rq;
DEFINE_RAW_SPINLOCK(global_rq_lock);
put_prev_task
Just noop. Since heater is FIFO, the next task will still be him.
- If task waits, handled by
dequeue
Make Default Scheduler
These functions will end up calling the
__*functions incore.c
To make default, in linux/init/init_task.c
- Also do some initialization
struct task_struct init_task = {
// ...
.policy = SCHED_FREEZER,
// ...
.freezer = {
.list = LIST_HEAD_INIT(init_task.freezer.list),
.time_slice = FREEZER_TIMESLICE,
},
.heater = {
.list = LIST_HEAD_INIT(init_task.heater.list)
},
};
linux/kernel/kthread.c
static int kthread(void *_create) {
// ...
sched_setscheduler_nocheck(current, SCHED_FREEZER, ¶m);
};