
OS Notes: ASP
Published:
1-2. Intro
Abstraction and protection
Early OS
Just a library of standard features
- Assume one program at a time
- No malicious program
- Poor utilization (idle)
Solution: protection
- Preemption: reclaim CPU from a running process
- Kernel regains control whenever interval timer fires
- Supervisor mode
- Access control
Preemption
#include <sys/time.h>
#include <sys/stat.h>
#include <assert.h>
double GetTime() {
struct timeval t;
int rc = gettimeofday(&t, NULL);
assert(rc == 0);
return (double) t.tv_sec + (double) t.tv_usec/1e6;
}
void Spin(int howlong) {
double t = GetTime();
while ((GetTime() - t) < (double) howlong)
; // do nothing in loop
}
int main(int argc, char *argv[]) {
char *str = argv[1];
while (1) {
Spin(1);
printf("%s\n", str);
}
}
Protection
Can break the system with fork() bomb
- Limit number of processes/CPU
- Kill misbehaving programs
Interposition
- Check if accesses are legal
OS Structures
- Monolithic: app directly above OS
- Microkernel: app with modular design, called through system calls
- Resilience to application bugs
Memory
If you can’t name it, you can’t touch it
Address translation (done in HW) 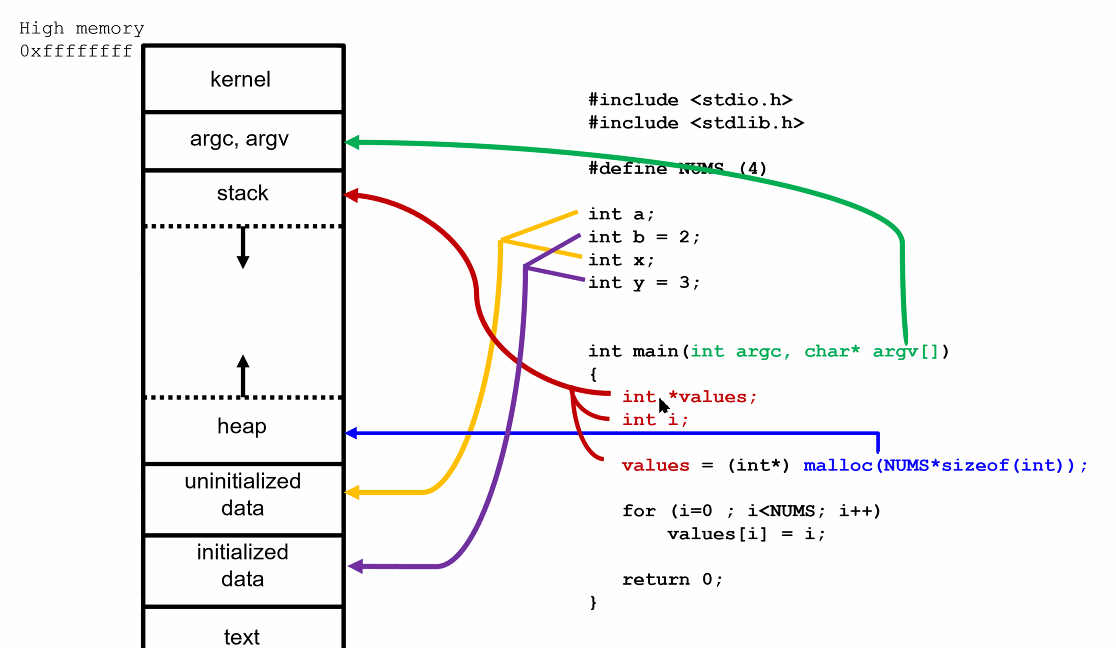
Advantages
- Kernel-only VA
- Can’t touched by apps
- Read-only VA
- Sharing code pages (libraries)
- Inter-process communication, memory mapping
- Disable execution
System contexts
- User-level
- Kernel process context: syscall, exception handling
- Kernel code not associated with process: timer/device interrupt
- Context switch code: change the running process
- Idle
Multitasking
Context switching is not always better, if a lot of memory required
stracetells the traces of the syscalls
HW1 Linked List
- Linear movement (not good at random access)
- Circular doubly linked
#include <linux/list.h>
struct list_head {
struct list_head *next;
struct list_head *prev;
};
struct fox {
// data
struct list_head list; // value, not pointer
};
Find the parent structure with only a pointer to its field (find fox from list_head)
#define container_of(ptr, type, member) ({ const typeof( ((type *)0)->member ) *__mptr = (ptr); (type *)( (char *)__mptr - offsetof(type,member) );})
struct fox *red_fox;
red_fox = kmalloc(sizeof(*red_fox), GFP_KERNEL);
INIT_LIST_HEAD(&red_fox->list);
List Head
Special head pointer. Created with macro:
static LIST_HEAD(head);
Manipulation
#include <linux/list.h>
list_add(struct list_head *new, struct list_head *head);
// add immediately after head
list_add_tail(struct list_head *new, struct list_head *head);
// add immediately BEFORE head
list_del(struct list_head *entry);
// does not free any memory
list_del_init(struct list_head *entry);
// delete, then reinitialize
Traversal
list_for_each_entry(pos, head, member)
pos: a temporary pointer for the iterated variablehead: pointer to thelist_headnodemember: variable name ofstruct list_headinpos
Remove
list_for_each_entry_safe(pos, next, head, member)
nextused to store the next list entry, so it’s safe to remove the current entry
3. Linux
- Firmware code performs a power-on self test, pre-initializes hardware
- Firmware checks Master Boot Record (MBR) of hard disks to identify a bootable partition
- Bootloader in MBR reads configuration files, loads and launches the kernel from the disk
Booting Linux
- Kernel program starts
- Hardware configures, including VA
- Start process 0
- Virtual task
- Start scheduler
- Process 0
forks process 1 to runkernel_init - Process 0 becomes the idle task, calls schedule
- Schedule context switches to other processes from
runqueue - Process 1 will run and
execveto “/init” initis a regular program, such assystemd- At some point, we return to kernel again
Processes
- If a process’s parent dies before reaping the child, it becomes an orphan, get adopted by process
init - If child dies, before the parent reaps it, it’s a zombie process
- Becomes
<defunct>in the process tree
- Becomes
Kernel Modules
Kernel Module Interface to dynamically link object files into running kernel
Create a Module
#include <linux/module.h>
#include <linux/printk.h>
// called whem loaded
int hello(void) {
printk(KERN_INFO "Hello\n");
return 0; // return an error code
}
// called when removed
void goodbye(void) {
printk(KERN_INFO "Goodbye\n");
}
// register module entry and exit points
module_init(hello);
module_exit(goodbye);
// metadata
MODULE_DESCRIPTION("A basic Hello World module");
MODULE_AUTHOR("cs4118");
MODULE_LICENSE("GPL");
Build a Module
obj-m += hello.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
obj-m: object files to be built for kernelobj-y: object file to be linked to main kernel image (we’re dynamically loading)
-Cchanges the directory to/lib/modules/$(shell uname -r)/build$(shell uname -r): evaluateuname -r(kernel release) withshell
- The folder contains the kernel
Makefile M=$(PWD)allows thisMakefileto move to module source directory before trying to buildmodulesorclean
Load a Module
sudo su
insmod hello.ko
lsmod # check mods installed
rmmod hello # no need for .ko
Read the kernel log buffer:
dmesg
dmesg -c # clean the buffer
dmesg -level=warn
Fault
If a fault happens in your kernel module, kernel will jump to exception handlers
- Kernel provides two levels of fault handler.
- Beyond that, kernel crashes
- Due to limited hardware support
Symbol Scope
Exported symbols are visible to any loadable module
- Dynamically linked to the kernel
#include <linux/module.h>
#include <linux/init.h>
#include <linux/kernel.h>
static int rday_1 = 1;
int rday_2 = 2;
int rday_3 = 3;
EXPORT_SYMBOL(rday_3);
static int __init hi(void) {
printk(KERN_INFO "module m2 being loaded.n");
return 0;
}
static void __exit bye(void)
printk(KERN_INFO "module m2 being unloaded.n");
module_init(hi);
module_exit(bye);
rday_1does not show in symtab, not show up in kernel spacerday_2andrday_3flagged as global data objectsrday_3has an entry in the module string table and symbol table, inksymtabandkstrtab
4.1 Signals
See ASP Signals
4.2 File IO
See ASP File IO
5.1 IPC
See ASP IPC and ASP Synchronization
5.2 Threads
See ASP Threads
6 Advanced IO
See ASP Advanced IO
7. System Calls
Interrupts
See ASP Interrupts
Parameters
Passed via registers. If larger, use a struct pointer (E. struct sigaction)
Convention for function calls (typical):
- Arguments passed through registers
- Sometimes as stack offsets
- Volatile: may be changed on return
- Non-volatile: must be saved and restored by callee
- Encoded in Application Binary Interface (ABI)
Need to validate buffer, need to check boundary and permissions, to avoid writing to kernel memory, since will enter kernel mode
Kernel Actions
Need to enter and return kernel mode, branch to the position of sys_read() function in the kernel 
E. Address Space
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#define BLKSZ (1<<22) // 4MB
void wait4input(const char* msg) { puts(msg); getchar(); }
int main() {
char* arr;
int i,j;
printf("mypid=%d\n",getpid());
wait4input("before big loop");
for (i=0;i<1000;i++) {
//wait4input("before malloc");
arr = malloc( BLKSZ );
for (j=0;j<BLKSZ;j++)
arr[j] = '1';
}
wait4input("done");
return 0;
}
Go to the process filesystem
cd /proc/2265
cat maps # shows entire addresss space
Get a block on the heap Modern allocators use mmap() instead of repeatedly calling brk()
mmap()more flexible,brk()forces a contiguous region
HW3
System Calls
asmlinkage long sys_getpid(getpid) // maxro SYSCALL_DEFINE0(getpid)
{
return task_tgid_vnr(current); // returns current->tgid, long
}
asmlinkagetell compiler to look only on the stack for arguments- Required for any syscalls
- Return
longin kernel andintin user space sys_*naming convention
Implementation
- Verify parameters
- Pointers
copy_to_user(dst, src, size)writes into user spacecopy_from_user()reads from user space- Return num bytes failed to copy on error
SYSCALL_DEFINE3(silly_copy,
unsigned long *, src, unsigned long *, dst, unsigned long len)
{
unsigned long buf;
if (copy_from_user(&buf, src, len))
return -EFAULT;
if (copy_to_user(dst, &buf, len))
return -EFAULT;
return len;
}
- Check capability
SYSCALL_DEFINE4(reboot,
int, magic1, int, magic2, unsigned int, cmd, void __user *, arg)
{
if (!capable(CAP_SYS_BOOT))
return -EPERM;
// ...
}
Kernel in process context during syscall execution,
currentpointer points to current task- Can sleep (E. blocking call), preemptible
Registration
- Add entry to the end of syscall table
- For each architecture
- Define syscall number in
<asm/unistd.h>- Syscall number can’t be reused
- All registered syscalls in
sys_call_table
- Compile into kernel image
8. Run/Wait Queues
Test code that times gettimeofday() calls
- Inconsistent results
- Due to scheduling and interrupts
If test library calls to syscall, much slower
- User library reads from kernel directly, avoiding the actual
syscall()trap overhead
Same for opening a file
Process States
In Linux, task can be a process/thread
#define TASK_RUNNING 0x0000
#define TASK_INTERRUPTIBLE 0x0001
#define TASK_UNINTERRUPTIBLE 0x0002
- Running: runnable (running, or waiting to run)
- Interruptible: sleep waiting for something, can be awakened if a signal received
- Uninterruptible: also sleep waiting, but can’t be awakened
Run Queue
A linked list of task_struct via children and sibling
Each CPU has a run_queue, links tasks with TASK_RUNNING state
- With a separate
list_head, and its own disjoint run queue
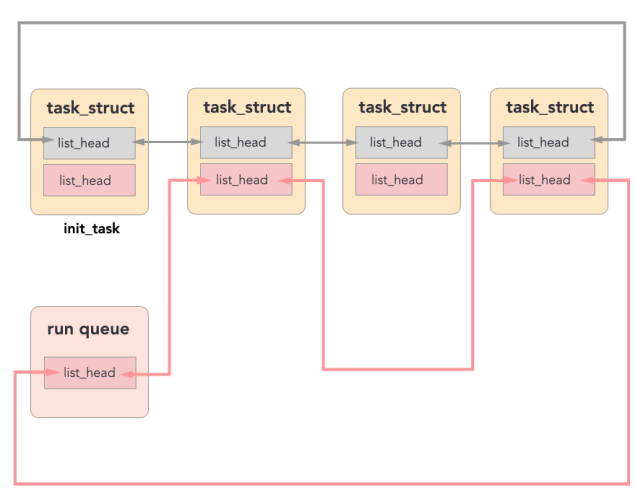
Wait Queue
Not embedded in task_struct
- In fact, a parent of
task_struct - Since don’t know which element to wake up
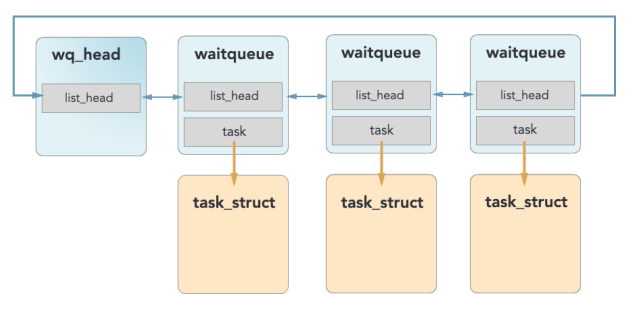
Data Structures
struct wait_queue_head {
spin_lock_t lock;
struct list_head task_list;
};
struct waitqueue {
struct task_struct *task;
wait_queue_func_t func; // callback function for wait condition
struct list_head entry;
}
Interface
#include <linux/wait.h>
wait_event_interruptible()
// a bit outdated, doens't account for synchronization
Functions:
prepare_to_wait(): add to wait queue, change state toTASK_INTERRUPTIBLEsignal_pending(): check for signals that interrupt wakeup, if so, breakschedule(): save state and sleepfinish_wait(): change state toTASK_RUNNING, remove from wait queue
Scheduling
pick_next_task(): choose a new task from run queuecontext_switch(): put current task to sleep, and start running new task
Sleeping
wait_event(): issue a wait object- Enqueue on wait queue
- Remove from run queue
schedule()pick_next_task()context_switch()
- Run other tasks
Waking Up
- When event happens,
wake_up() - Call
try_to_wake_up()on each task - Enqueue those on run queue
- Wait for other task to call
schedule(). Choose a sleeping task - Sleeping task checks condition again. If true,
finish_wake()Never go back directly to running on CPU
States
- Running on CPU
- To sleep:
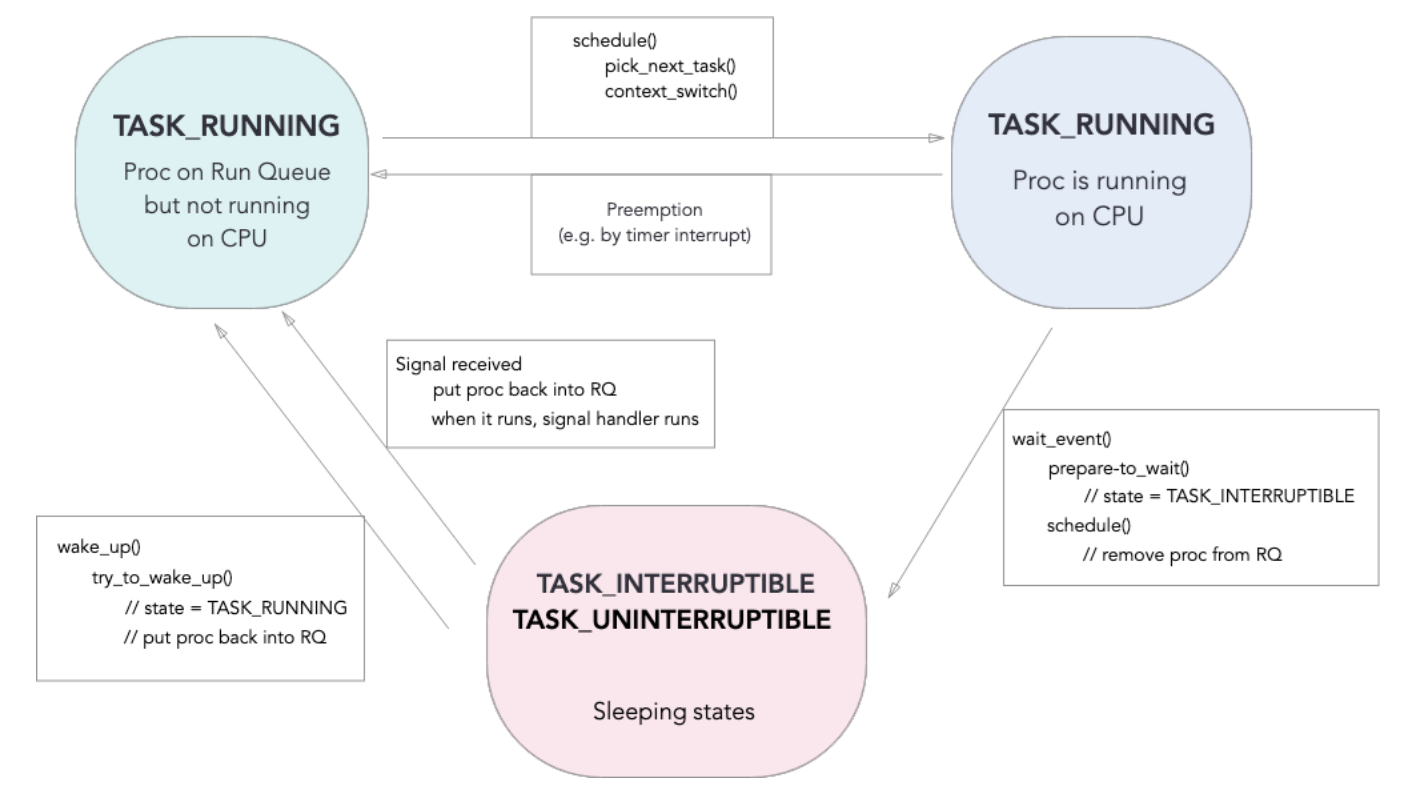
E. read()
- Trap into kernel
- Save registers into kernel stack
- Device driver issues IO request to device
- Put calling process to sleep
- Another process starts running
- Device receives input, raise a hardware interrupt
- Trap into kernel again, enqueue the next process
- Current ask eventually calls
schedule()- Another process on the run queue starts running
Context Switch
(easier in ARM)
Current task blocks OR preemption via interrupt
- Release CPU registers (written in assembly)
Preemption
If a process does not give up the CPU
- Use external timer to interrupt
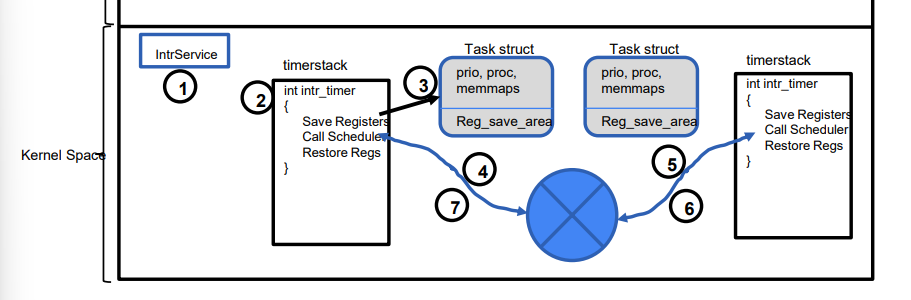
9. Interrupts
Interrupt Contexts
Limitations: can’t sleep
- No associated task running, can’t interact with wait queue and
schedule()- Don’t know when can wake up
kmalloc(),copy_to_user()may trigger IO, can’t be called from interrupt context All handlers share one interrupt stack per processor
Handling
Idea: Defer most work for later, only time-critical ones
- Top half (first level)
- ACK the interrupt
- Fast, to make CPU get back to work
- Bottom Half (second level)
- Bulk process when CPU idle (E. large file received over network)
- Kernel tasklet, threads - Single interrupts will not nest, no need to be reentrant
- Can be interrupted by another type of interrupt
E. network package arrival
- Top half: ACK arrival, move from NIC to memory, prepare for future packets
- Bottom half: propagate through networking stack (TCP/IP), can be deferred
Sync
All concurrent data must be protected
Mutex (Sleeping)
pthread_mutex_locK(&balance_lock);
++balance;
pthread_mutex_unlock(&balance_lock);
Calling task put to sleep while waiting for lock
Is sleeping always a good idea?
- Bad: sleep overhead
Spin Lock
No preemption
Interrupt still normal, but the task can’t be rescheduled
- With
preempt_count, only sleepable when 0
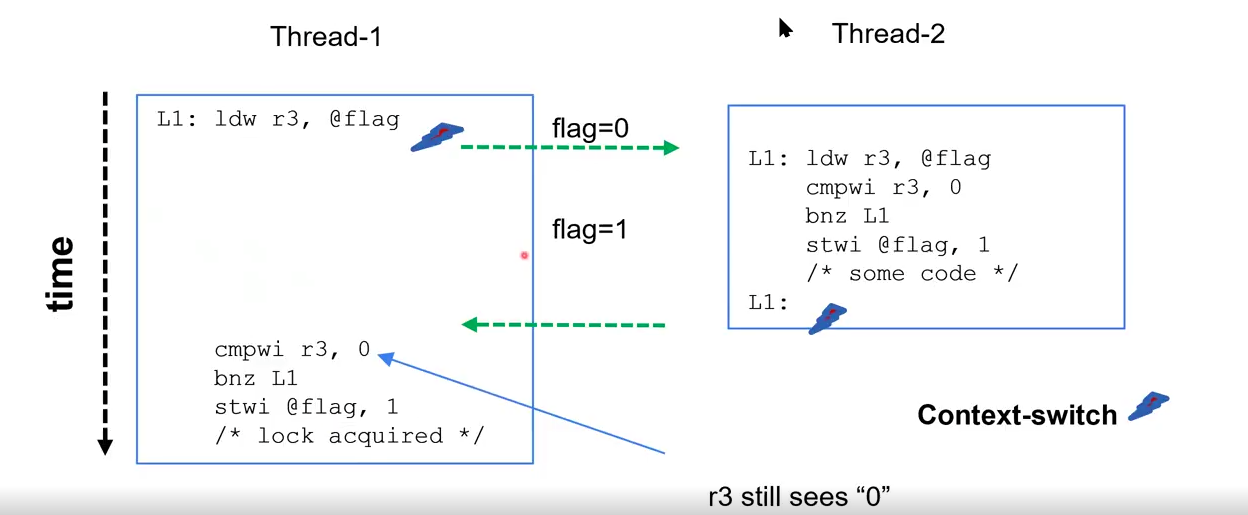
int flag = 0;
lock() {
while (flag == 0) {; }
flag = 1;
}
unlock() {
flag = 0;
}
Issues
- Multithread race condition. Need atomic
- Waste CPU cycles Both threads assume ownership:
Need atomic instruction test_and_set(&flag)
Hardware pseudocode:
int test_and_set(int *lock) {
int old = *lock;
*lock = 1;
return old;
}
Linux Spin Lock
spin_lock() and spin_unlock()
- Want keep critical sections small
- Must not lose CPU while holding lock
- Must not call any function that may sleep
- E.
kmalloc(),copy_from_user()
- E.
- Prevents kernel preemption
++preempt_count
- OK for hardware interrupt, unless handler also tries to lock
- Deadlock
- Used by process context or a single interrupt
IRQ: interrupt request
spin_lock_irqsave(), spin_lock_irqrestore()
- Lock a shared resource that may be used by interrupt handler
- Saves current interrupt state, then disable all interrupts on local CPU
- Restored later
- Used by process and interrupt contexts; or more than 1 interrupts
spin_lock_irq(), spin_unlock_irq()
Preemption
Kernel forcefully reclaim CPU
- Track a per-process
TIF_NEED_RESCHEDflag preempt_counttracks how many atomic states CPU entered. Can’t preempt if nonzero- If set, preemption by calling
schecule()when:- Return to user space (from syscall or interrupt handler)
- Return to kernel from interrupt handler, only if
preempt_countis zero preempt_count = 0, (E. right after releasing lock)- Task in kernel mode calls
schedule()itself (E. blocking syscall)
10. Synchronization
- Safety: Mutex
- Liveliness (progress):
- must allow one to proceed;
- must not depend on threads out of critical section
- Bounded waiting
- No assumptions on speed and CPU count
1. Disable Interrupts
lock() { disable_interrupt(); }
unlock() {enable_interrupt(); }
Bad:
- Privileged operations, user program can’t use
- Can’t work on multiprocessors (
*_interrupt()only applies for current CPU)- Can’t have long critical sections
2. Software Spin Lock
int flag[2] = {0, 0};
lock() {
flag[self] = 1;
while (flag[1 - self] == 1)
;
}
unlock()
flag[self] = 0;
Not live: can deadlock, race condition
int turn = 0;
lock() {
while (turn == 1 - self)
;
}
unlock()
turn = 1 - self;
Not live: Can’t enter twice in a row
Peterson
Assume:
- Load and store are atomic
- In-order execution
int turn = 0;
int flag[2] = {0, 0};
lock() {
flag[self] = 1; // I need lock
turn = 1 - self; // I take the turn
while (flag[1-self] == 1 && turn == 1 - self)
;
}
unlock()
flag[self] = 0;
Spin while
- Other thread needs lock, AND
- It’s other thread’s turn
turnacts as tie-breaker to prevent deadlock when both threads are “polite” - The last thread to write
turnyields to the other
Bad if reordered
Memory access (loadflag[1-self]) will typically be reordered up
3. Hardware Spin Lock
Fence
Ensure all memory operations are in-order before processing
- expensive
mfence: all memorylfence: all loadssfence: all stores
lock() {
flag[self] = 1;
sfence;
while (flag[1-self] == 1 && turn = 1-self)
;
}
Atomic Test-Set
x86
Use xchgl to atomically swap two locations
long test_and_set(volatile long *lock) {
int old;
asm("xchgl %0 %1"
: "=r"(old), "+m"(*lock) // output
: "0"(1) // input
: "memory" // clobber
);
return old;
}
"=r"(old)write to (general purpose) registerold- After the swap
"+m"(*lock)read and write to memory*lock"0"(1)initializesoldto 1- Put 1 into operand
0(old, will be returned)
- Put 1 into operand
"memory"avoids compiler optimization on memory
4. Sleep Lock
lock() {
while (test_and_set(&flag))) {
add_wait_queue();
schedule();
}
// do critical section
}
unlock() {
flag = 0;
if (/* thread in wait queue */)
// wake up one thread
}
Issues
- Lost wakeup
- After calling TS, before adding to wait queue; other thread unlocks
- Wrong thread gets lock
- Newer threads may steal the lock
- Fix: make
unlock()directly transfer to waiting thread
Fix by adding a guard lock to avoid losing wakeups
prepared_to_yield()to protect the gap betweenguard = 0andyield()
typedef struct mutex_t {
int flag;
int guard;
queue_t *q;
};
void lock(mutex_t *m) {
while (test_and_set(m->guard)) // begin protected
;
if (m->flag == 0) { // mutex available
m->flag = 1;
m->guard = 0;
} else { // unavailable, sleep again
enqueue(m->q, self);
prepare_to_yield(); // prepare to yield
m->guard = 0; // end protected
yield();
}
}
void unlock(mutex_t *m) {
while(test_and_set(m->guard)) // begin protected
;
if (queue_empty(m->q))
m->flag = 0;
else // transfer to next thread DIRECTLY
wakeup(dequeue(m->q));
m->guard = 0; // end protected
}
RW Lock
- Read lock (shared): multiple may hold
- Write lock (exclusive): only one can hold
struct rwlock_t {
int nreader;
lock_t guard;
lock_t lock;
};
write_lock(rwlock_t *l)
lock(&l->lock);
write_unlock(rwlock_t *l)
unlock(&l->lock);
read_lock(rwlock_t *l) {
lock(&l->guard);
++nreader;
if (nreader == 1) // first reader
lock(&l->lock);
unlock(&l->guard);
}
read_unlock(rwlock_t *l) {
lock(&l->guard);
--nreader
if (nreader == 0);
unlock(&l->lock);
unlock(&l->guard);
}
Writer will be starved
Need to kick readers out for write requests
Anti-Starve
Use a writer lock, so when writer is waiting for the actual lock, no new readers can add themselves
- Existing readers will drain and release
lock
struct rwlock_t {
int nreader;
lock_t guard;
lock_t lock;
lock_t writer;
};
write_lock(rwlock_t *l) {
lock(&l->writer);
lock(&l->lock);
unlock(&l->writer);
}
read_lock(rwlock_t *l) {
lock(&l->writer);
lock(&l->guard);
++nreader;
if (nreader == 1) // first reader
lock(&l->lock);
unlock(&l->guard);
unlock(&l->writer);
}
Semaphore
Now kernel context
class Semaphore {
int lockvar; // atomicity
int value;
Queue<Thread*> waitQ;
void Init(int v);
void P(); // down
void V(); // up
}
void Semaphore::Init(int v) {
value = v;
waitQ.init();
}
If run out of resources, add yourself to wait queue
- Must be atomic
- First line disable interrupts
- Last line enable interrupts
- Spin lock, since critical
void Semaphore::P() {
lock(&lockvar);
value--;
if (value < 0) {
waitQ.add(current_thread);
current_thread->status = blocked
unlock(&lockvar);
schedule();
} else
unlock(&lockvar);
}
void Semaphore::V() {
lock(&lockvar);
value++;
if (value <= 0) {
Thread *thd = waitQ.getNextThread();
scheduler->addd(thd);
}
unlock(&lockvar);
}
E. Linux pipe Producer-Consumer
- Block producer when buffer full
- Block consumer if no data
Ring buffer:
Semaphore empty = N;
Semaphore full = 0;
Mutex mutex = 1;
T buffer[N];
int widx = 0, ridx = 0
Producer (T item) {
P(&empty);
P(&mutex);
buffer[widx] = item;
widx = (widx+1) % N;
V(&mutex);
V(&full);
}
// same for consumer, P(full); V(empty)
- If move buffer R/W outside of
mutex, won’t work
E. Barrier
Coordinate multiple threads to all reach a specific point before allowed to continue
- Rendezvous: waiting point
- Critical point: no thread allowed to execute until everyone reach Rendezvous
rendezous:
sem_wait(mutex);
count++;
if (count == n)
sem_post(barrier);
sem_post(mutex);
sem_wait(barrier);
sem_post(barrier); // reusable barrier, wakes up the next thread
critical_point:
sem_wait(mutex);
count--;
if (count == 0)
sem_wait(barrier); // comsumes the final post left floating
sem_post(mutex);
Can use interlocking barrier2 with barrier for critical_points in a loop
RCU
Lock-free Synchronization
Problem: RW lock very slow
- Writes not happen often
- Doesn’t scale with large number of CPUs
Read-Copy-Update
- Multiple readers and one writer and run simultaneously
- Reader may read old, but consistent data
For reading, make a copy of the shared resource
For writing, (locked) allocate a new resource, and shared the pointer to it
struct foo {
int a;
int b;
} *global_foo;
// global_foo initialized elsewhere
DEFINE_SPINLOCK(foo_lock);
void get(int *p, int *q) {
struct foo *copy_foo;
// 1) begin reading (no lock)
rcu_read_lock();
// 2) copy pointer once
copy_foo = rcu_dereference(global_foo);
// 3) access data using copy_foo
*p = copy_foo->a;
*q = copy_foo->b;
// 4) end reading (no unlock)
rcu_read_unlock();
}
rcu_dereferencegrabs the pointer- Includes memory barrier
void set(int x, int y) {
struct foo *new_foo = kmalloc(...);
struct foo *old_foo;
// 1) synchronize multiple writers
spin_lock(&foo_lock);
// 2) copy old pointer once
old_foo = rcu_dereference_protected(
global_foo, lockdep_is_held(&foo_lock));
// 3) update data
new_foo->a = old_foo->a + x;
new_foo->b = old_foo->b + y;
// 4) switch pointer
rcu_assign_pointer(global_foo, new_foo);
spin_unlock(&foo_lock);
// 5) wait a for old readers to finish
synchronize_rcu();
// 6) free old struct
kfree(old_foo);
}
synchronize_rcu(): tells writer to wait until every single active reader has finished- safe to
kfree()after
- safe to
In Linux Kernel Implemented as a compiler optimization to reorder the critical sections properly
Summary
- Spinlocks: Small, fast, non-sleeping locks used when holding time is short, such as in interrupt handlers.
- Mutexes: Sleeping locks for mutual exclusion, offering better performance for longer critical sections where sleeping is allowed.
- Semaphores: Traditional locks that can allow multiple holders, used for complex synchronization.
- Read/Write Locks (rwlock / rwsem): Allow multiple simultaneous readers but only one exclusive writer.
- Read-Copy-Update (RCU): A mechanism for high-read-frequency scenarios, allowing readers to run without locks.
Lock Contention
Failed lock acquire
Function of:
- Frequency of attempts
- Lock hold time
- Number of threads
Monitoring
Object with a set of monitor procedures
- One one active thread at a time
- Java
synchronized- 1 Mutex + N condition variables in a class object