
3-Synchronization
Published:
Need memory consistency and cache coherence
Parallelism
- ILP: OOO speculation, RR
- DLP: SIMD, SIMT (multithread)
- T(Thread)LP: Synchronization, coherence, consistency, interconnection Reading: Synthesis lectures on coherence, consistency, and interconnection networks
Minimal Parallel Computer
To compute x--
Rx <- ld x
sub Rx, Rx, 1
st Rx -> x
Synchronization
Issue: race condition on multiple processors
Lock
Add a lock instruction to the ISA.
- Acquire:
lock x, one processor has exclusive access tox - Release:
unlock xlockandunlocksignaled to arbiter, granting permission to one of the processors. xis mutual exclusion: shared variables can be exclusively handled by a piece of code- If program fails to unlock: starvation: other threads can’t make progress
lock L
Rx <- ld x
sub Rx, Rx, 1
st Rx -> x
unlock L
Issue: lock and shared variable is in memory. Need to cache in processor cache
- After lock updated in cache, need to go to arbiter and unlock it.
xneeds to be propagated to memory so that other processors can get the latest value ofx- Operation becomes
Lock L- Shared variable update
Unlock- Tell arbiter to unlock
Flush LFlush x
- May need protocol to forward cache values
Solutions
- Send arithmetic operations to memory (Atomic RMW (read, modify, write) instruction). Mark certain regions of code for shared variables and locks as uncacheable
- RMW happens without any interruption
- Make centralized cache for shared variables and locks (in GPU)
- Transactional memory, detect conflicting operation, rollback, and serialize
TS
RMW happens without any interruption Let RMW be “test & set instruction” (atomic)
TS: # atomic block
Rx <- ld x
st 1 -> x # unconditional write
- Reads the value of
x, return the value - Sets
x=1In modern processors, use Compare And Swap (CAS), store the value of a registerRvalintox
Lock routine
loop:
Rx <- TS x
BNEZ Rx, loop # spin if Rx == 1
Unlock routine
st, 0, x
Suppose T1 locks the variable.
- Executing
TS, atomically updatex=1. SupposeT2wants to get lock, readsx=1from register T1Do process.T2spins- After unlock,
T1resetx=0
Shared variables set as uncacheable. Everything goes to memory
Performance
- Not great, serial section in mutex
- No OOO
Ideally, have some mechanism that will automatically take shared variables and place them into cache.
Performance
What is the latency of lock acquire and release?
- Need to compute the number of bus transactions needed before a lock acquire/ release
- Uncontended lock acquire
- Lock variable is not in the cache. In
invalidstate - Write: move from
invalidtomodified, broadcasting it getting the lock
- Lock variable is not in the cache. In
- Contended lock acquire (TTS)
Assume one other thread wants to acq. Thread 1 has lock inmodified- Thread 2 tries to read the lock, executes
TS(unconditionally writes a 1). Need to get a copy of the cache block in exclusive state. The write invalidates the thread 1 cached copy. - Thread 1 goes from
Modified->Invalid, thread 2 goes fromInvalidtoSharedtoModified- Thread 2 does not get access to the lock, but still writes a “1” to it
- This write process still invalidate the lock
- If thread 3, thread 3 also goes to
Invalid - Bus flooded with such traffic. Lock release is slowed down
- Worse: the cores keep spinning! Not just one cycle of contention!
- Thread 2 tries to read the lock, executes
- Contended lock release (terrible performance)
- Owner can’t execute
store 0 -> xinstruction, need to wait for every previous lock write traffic.
- Owner can’t execute
TTS
Solution: TTS lock. Before writing, first LD the lock variable. Check if lock is acquirable (BRNZ)
loop:
LD x
BRNZ loop
TS x
BRNZ loop
- Instead of going from
ModifiedtoInvalid, all threads go toShared(read-only copy)- At unlock, all
Sharedwill be written ->Invalid - Make unlock very cheap by adding another test before TS
- At unlock, all
Load linked and Store conditional
Make store in TS conditional on writes that have happened in other cores
LL x- Load
x - Internally remember the link, set a flag if someone else writes to this location
- Load
SC x- Attempts to store to
xonly if it’s not written by someone else after lastLL - Else, go back and get lock again
- Attempts to store to
Lock:
Rx <- LL x
BRNZ Rx, Lock # if x != 0, someone has the lock, retry
Rx <- SC x
BRNZ, Rx, Lock # if SC failed, retry
Consistency Mechanism
Suppose you have location x and y in memory
Thread 1:
1 ld x
2 st x
Thread 2:
3 ld y
4 st y
Consistency: How does each thread see updates to other variables in the memory?
- Can I interleave the updates of location
ywith locationx? - Are all orders of 1234 OK? What are the valid orders in which multiple memory locations can be updated
- Coherence is about one memory location
Consistency model: rules for memory
1. Sequential Consistency (SC)
Can’t be reordered
- If \(LD(x) <_{po} LD(y)\), then \(LD(x) <_{eo} LD(y)\)
- Same for
st - If \(LD(x) < _{po} ST(y)\), then \(LD(x) <_{eo} ST(y)\)
- Same other for
stfollowed byldForbids OOO memory reordering in a single core
2. Relaxed Consistency
Reordering is forbidden only when the programmer wants it to happen Introduces a new fence instruction: stop reordering instructions across the fence
Block A
------- Fence
Block B
------- Fence
Block C
When fence on, OOO turned off
- When
fencedecoded in HW, fetching is stopped, untilfencebecomes the oldest instruction in the pipeline.- Drain all memory buffers in pipeline
- (Decode serialization)
mfence: Do not allow reordering between the timing routine and other instructions that has happened before
- \(LD(x) <_{po} Fence\), then \(LD(x)<_{eo} Fence\)
- \(Fence <_{po} LD(x)\), …
- Same for store
- \(Fence_x <_{po} Fence_y\), then \(Fence_x < _{eo} Fence_y\)
3. Total Store Ordering (TSO)
Everything else can’t, but Store -> Load may be violated
- TSO has a store buffer
Lock-Free Algorithm
E. used to update a stack/linked list Use atomic operations (RMW)
- CAS (read a value from memory, compare it conditionally. If condition is true, write a different value back to a location): hardware instruction that does read, compare, and write in a single step
- E. adding two nodes simultaneously a linked list, when executing CAS, read the tail pointer, and atomically swap to the pointer to one of the the two algorithms
Cache Coherence
if multiple cores R/W to the same address, which value is the correct one? Must provide two protocols
- Read request
- Write request with ack
Invariant rules
- SWMR (Single Writer Multiple Reader)
- Multiple writes not allowed
- Either
- A single core has RW access
- Multiple cores have read only access
- LVI: (Last Value Invariant)
- If multiple writes followed by a read, read always gets the last written value
Attach little controllers near cache and memory to communicate to ensure the properties above
- Communicating FSM
Assumptions
- Operate on cache block addresses. All transactions happen at granularity of cache lines (64 bytes)
- Request and responses are ordered
- Suppose core C1 sends a request. It needs to wait for its response before sending a second request (Snoopy protocol, bus)
- Across cores, it may be interleaved
- Else: pipelined
- Else: unordered (may get second response before the first). Need directory protocol, P2P
- Suppose core C1 sends a request. It needs to wait for its response before sending a second request (Snoopy protocol, bus)
Cache Controller
Take state definitions, and use SIMD table. Here’s a partially filled table of state transactions. Based on given info, fill out the rest
Application of concepts. Don’t memorize specific states, maybe given a new set of definitions
Practice: Coherence questions 1.1-7
Given a program, find outputs that legal under sequential consistency
Design Space
Dirty block: modified in lower-level cache but not in higher-level
- Need writeback after eviction
States
- Validity: has the most recent value
- Dirtiness: has the most recent value, but updates not written back to memory
- Exclusivity: only have one private copy
- Except in the shared LLC
- Ownership: responsible for responding the cache requests
- May not be evicted without transferring ownership
Modified: valid, exclusive, owned, and potentially dirty- Cache only has one valid copy
- Can read or write
Shared: valid but not exclusive, not dirty, not owned- Read-only copy
Invalid: Not valid
Transactions
Get: Obtain a blockPut: Evict a block
Protocols
- Snooping: Request by broadcasting a message to all other controllers. Owners respond
- Simple, can’t scale
- Directory: Requests managed to memory controller, and forwarded to appropriate caches
- Scalable, but slower (sent to home)
Snooping Protocols
Modified- Can read or write
Shared- Read only
Invalid- Can’t read or write
Actions:
- Issue
BusRd,BusEx - Send data if owner
Snoopy
Assume transactions are observable by all other cache controllers
- Implemented on a bus
- All cache controllers can observe bus traffic
- Ordered requests and responses In cache line, add additional coherence metadata to track the state Every cache block can be in one of three states:
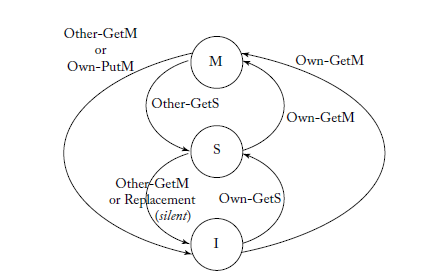
Invalid
LD(x)- Miss, issue
BusRD(x) - Transition to
Shared
- Miss, issue
ST(x)- Miss, issue
BusEx(x)to ask for exclusive access - Transition to
Modified
- Miss, issue
- Receive
BusRd(x)orBusEx(x)- Don’t care
Shared
- Don’t care
LD(x)- Hit, stay in
Shared
- Hit, stay in
St(x)- Issue
BusEx(x) - Transition to
Modified
- Issue
- Receive
BusRD(x)- NOP, let them read
- Optionally let them read
- Receive
BusEx(x)- Evict the cached item,
- Drop to
InvalidModfied
LD(x)orST(x)- Hit, stay in
Modified
- Hit, stay in
- Receive
BusRD(x)- Forward data, or writeback (
updateMem) - Drop to
Shared
- Forward data, or writeback (
- Receives
BusEX(x)- Forward or writeback
- Drop to
Invalid
Pipelined
FIFO buffer to handle requests and responses
- More buffer states in state machine
- More efficient
Directory protocols
Broadcast-based protocol (E. Snoopy) does not scale
A directory that maintains a global coherence view
- No state machine, all lookups happen at the central space
- Directory: computes the local LUT tracks which thread his the current owner to your director.
- Assume point-to-point ordering
Setup
8-core multiprocessor, shared SNUCA (you know exactly the cache bank from the address-) 64 MB chip shared L12 cache L1: 4 banks (that build each L1 chunk), address interleaved, set-associative, Multiple outstanding load misses (miss status handling), one rd, one wr port
- Allows simultaneous L/W in the same cycle, pipeline
- Store merging: when cache misses, take a break, and wait a while for new loads to come out, and then scare the original circuit. Share mass bulks of cache misses L2: 64 banks, address interleaved, SA, writeback, write-allocated (fetch data from low level, allocate it into cache), one
rd/wrport- L1 L2 connected with on -chip network
- Requests and replies are ordered (to the same node (dimensional order))
- Network header has 40 bits Physical implementation: along each L1 block, that hold all cache results from upper level to
Protocol
Metadata
- L1: Load, store, spill, directory message
- L2: directory transition table
States
invsharedmodifiedSM(S->M in progress, need to invalidate other sharers)MM(M->M in progress, need owner to writeback & invalidate) Transactions take multiple cycles (assumed to be atomic in snoopy)
Messages
Processor -> Directory
Share: request a shared cacheModify: request an exclusive cacherDAB(dirty writeback + eviction): send latest data from cache, unregister it from directoryrINV(clean eviction) Directory -> Processor (commands)NACK: Negative ACK, try again laterMACK: ACK for modify requestcDAB: Dirty Acknowledge back and invalidatecINT: Invalidate: ask to invalidate its copy
Hardware
L2
- Global coherence sate
- Presume vector (1 bit/core)
- Owner ID (for `modified)
- When you see more than 1 ones, the condition will be
Sharedas in SIMR - Suppose just one 1, state will be
ModifiedorShared - Suppose all 0, all will be
Invalid, need to decode from M2.
L1
- Current state
- (Optional) LSQ
L2 Side
Send NACK if transitioning to SM or MM, can’t immediately fulfill the request
| State | share | modify | rDAB (dirty) | rINV (clean) |
|---|---|---|---|---|
| I | Fetch from memory Send data -> Shared | Fetch from memory -> Modified | X | X |
| S | Add to sharer list Send data | Send MACK to requesterSend cINV to sharers-> SM | X | Remove sharer |
| M | Send cDAB to MSend NACK to requester-> SM | Send cDAB to MSend NACK to requester-> MM | Update data (remove sharer) -> Shared | Remove sharer -> Shared |
SM | Send NACK | Send NACK | X | Drop message |
MM | Send NACK | Send NACK | Update data -> Shared | -> Shared |
L1 Processor Side
Load
- Hit: Return load value
- Miss:
- If can be merged into an existing MSHR, send a
sharerequest - If unmergeable (standalone miss): one request per cycle
- Uncacheable (not part of coherence protocol): request directly to memory
- If can be merged into an existing MSHR, send a
Store
| L1 Hit | Load Type | Action |
|---|---|---|
| Yes | Modified | No action, update in cache |
| Yes | Shared | Request modifyStall commit until permissions obtained Need to make sure this is the oldest store. All speculation must be resolved |
| No | No matching load miss | No action, write around to L2 |
| No | Matching load miss (in MSHR) | Stall store commit until matching load is serviced. Then request modify to the previously written entry |
Spill
Spill L1 to make room for another block
- If clean, send
rINV - If dirty (modified), send
rDAB
L1 Message Handling
If receives… and hit:
cDABInvalidate + writebackcINV: InvalidateNACK: retry again If miss, ignore message
Dangers
- L1 stalls do not require circular waits (?)
- Dropped messages are redundant (due to ordered communication)
- Priority virtual channels, order:
- Mem -> L2
- L2 -> L1
- L2 -> mem
- L1 -> L2
- Buffer, with
NACKat holding sate
Interconnect Network
Bus, attached to
- Cache -> processor
- Memory Does not scale!!! You can’t tie too many things without affecting frequency
- As number of taps increase, frequency drops super-linearly
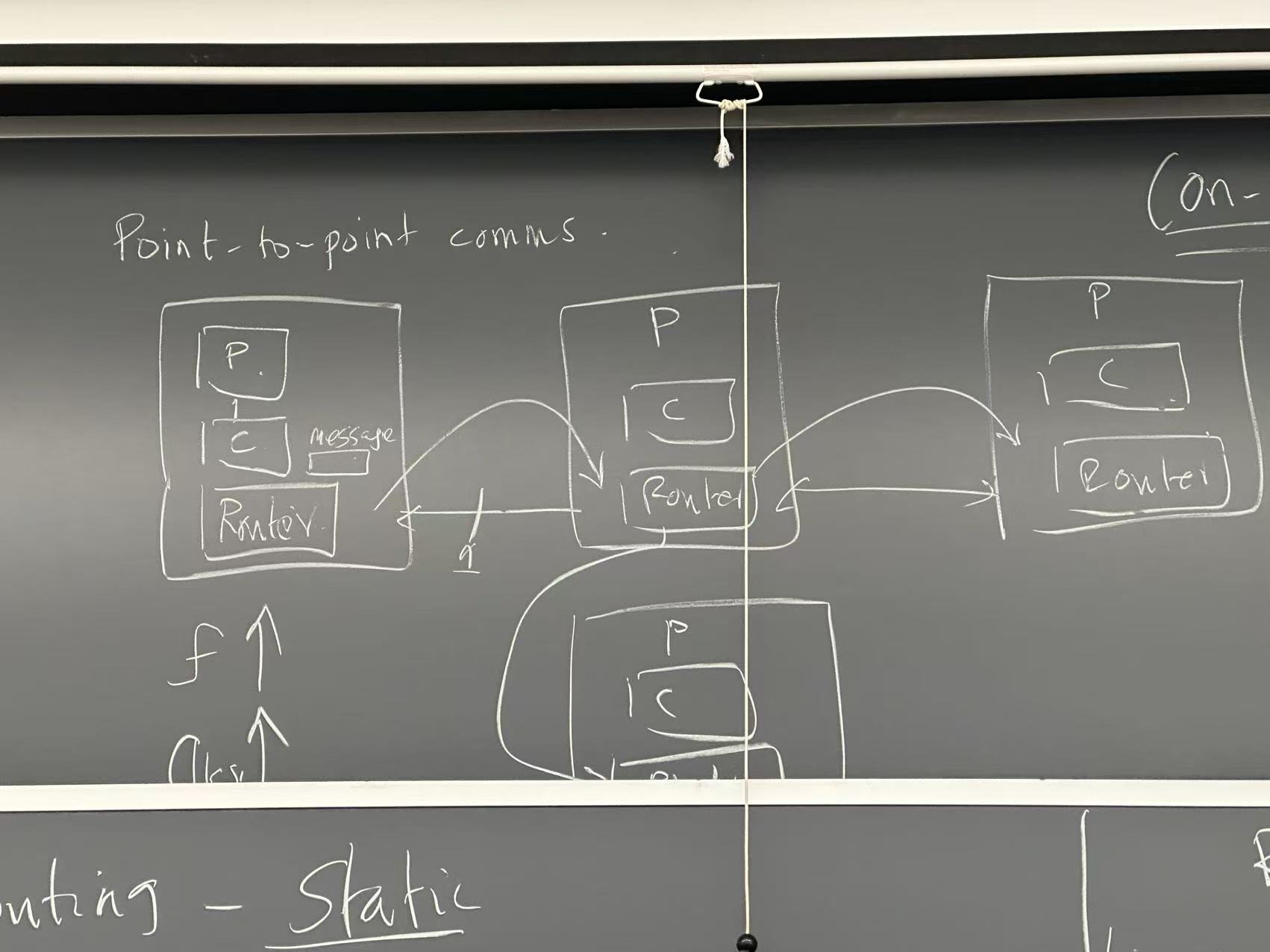
Need to add a router for point-to-point communications between the processors
- Router only connected to nearest neighbor
- Fast, since communication in very short distance
- Gain in clock frequency
- But need more clocks On-chip interconnection network
- Packet
- 1 valid bit
- Control info (from, to)
- Payload
- Payload may split to sub-packets (flit)
Design choices
- Topology (E. ring, mesh (2D), torus (2D ring))
- More complexity has lower latency, but more buffering (space) needed
- Routing
- Flow control
- What happens if you are unable to send a packet through a link (E. multiple flows to a single direction). Tell the sender to stop sending traffic
- Router microarchitecture (E. mesh)
- 5 input ports, 5 output ports (1 local, 4 from neighbor routers (NSWE))
- Input ports each has a fixed-size buffer
- Little controller to look at the head (control bits) of each buffer, determines which directions to send the package to
- A few crossbar (MUX) to route to output
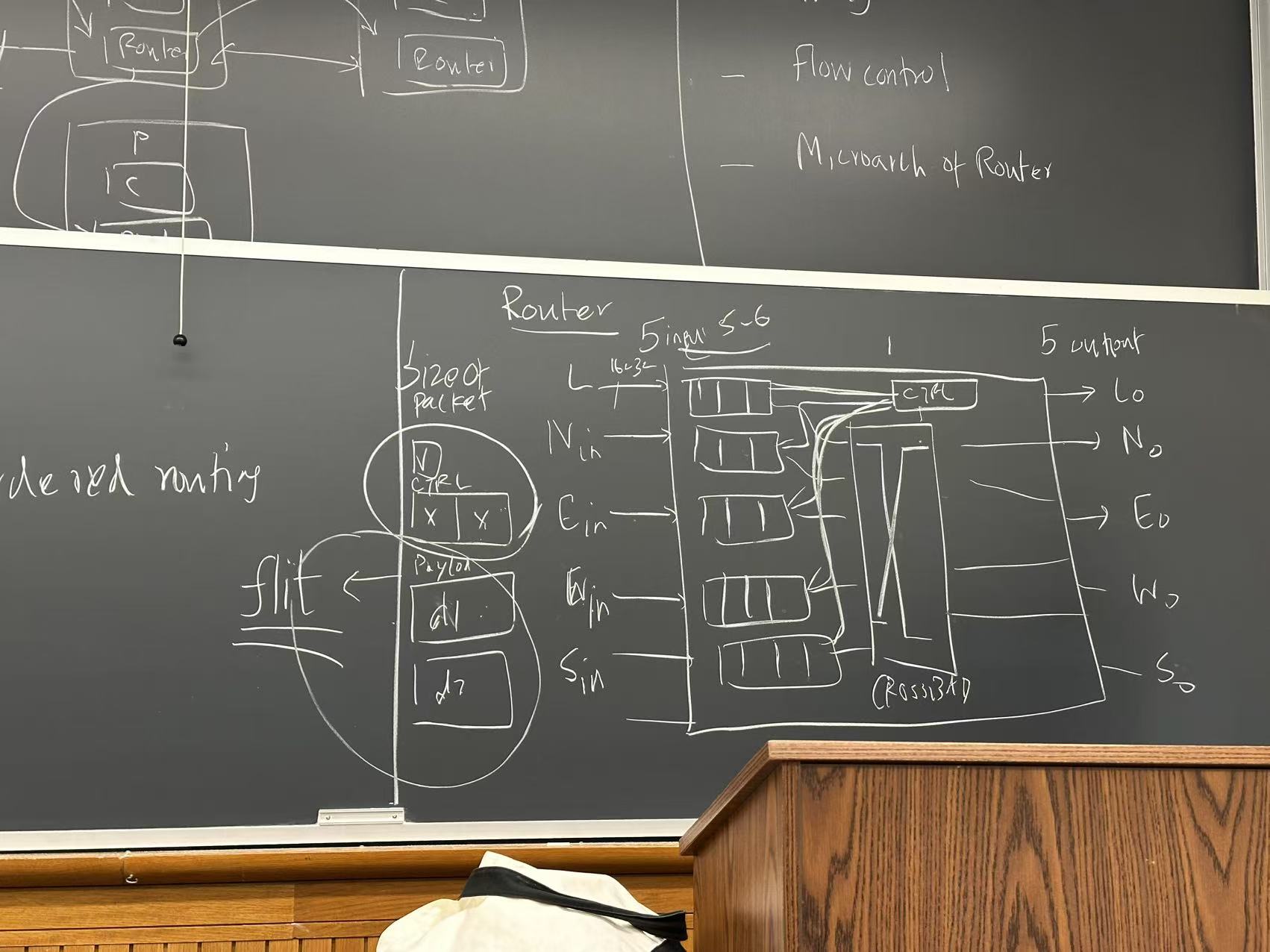
Conflict
when multiple inputs need to send to same output -> delayed -> need buffering (fairness policy)
- Controller needs to know the number of buffer free slots in downstream router (credit-based flow control)
- Need to report before full, not when full.
- Bisection bandwidth: max data can transmit from one end to the other
Lookup
- Look at local L1 first
- If miss, format a packet request and send through the router to neighbors
- Other core looks up the data and send back the cache line in a packet
- Receives data, caches into local L1
- If others also miss, goes to home node with M2 data
- How to locate which L2 bank to go to?
- Take the entire address space, go to the corresponding modulo tile