
Instagram Follower Scraper
Published:
A script to scrape the set of Instagram followers
Instagram lists your followers you don’t follow back, but not the opposite. The reason is obvious: Meta want you to look for more people to follow (back), instead of being a rat and unfollowing those that don’t.
Meta offers analytics for Instagram accounts. This is the conventional way: request the official data from Meta, and process the list of followers and following
See this link: https://www.reddit.com/r/Instagram/comments/yhazli/how_to_see_who_is_not_following_you_back_without/
However, the data takes a while to arrive (usually a few hours). I seek to find a faster way: scraping the Instagram website for a set of all the followers and following.
V1. BeautifulSoup
I wrote this version using BeautifulSoup a few months ago, where I first dragged the ins pages all the way to the end, downloaded the html files, and let bs4 do its job.
https://github.com/mg-04/mg-04.github.io/blob/main/docs/ins-follower/follower.py
Each of the list elements have <a> hyperlinks, so the code basically extracts all of them, and compares the set.
Instagram does not load the full following list after clicking the link (because there is too many to load). After you scroll to the bottom, it will load some additional content. This process needs to be repeated until the end is reached.
V2. Auto Scroller
As I gain more followers, however, this process of obtaining the html document becomes longer and longer, and I’m looking for a script to automate this. Again, chatgpt for the save.
Instagram’s html elements are heavily obfuscated, and we need to F12 the elements to locate their classes.
https://github.com/mg-04/mg-04.github.io/blob/main/docs/ins-follower/autoscroll.py
I used selenium for the web driver. The steps are follows:
- Log in to Instagram
- Click the “Followers” button
- Locate the
<a>element with keyword “Followers” - Click the button and wait for the page to load
- Locate the
- Locate the
dialogelement, whose class name contains “xyi19xy” - Scroll to the bottom of the dialog
- until the height of the dialog element no longer changes
Now we have automatically loaded the html file. It’s time to process it
- We can technically download it, and use the old
bscode from that point, but we can also useSeleniumto find the elements containing the usernames.
- Locate the
<div>elements- class name containing “x1dm5mii”
- Extract usernames from the elements
- Look for the
<a>tags linking to usernames, and extract theirhrefURL
- Look for the
- Compile all followers and following to a
set, and compare the usernames.
Usage
Login Credentials
To use it, simply input your username and password (of course those won’t go to me!)
You can bypass (some parts of) the login process if
- The account of interest is public
- You are a friend of the private account (aka you can access its followers/ing list)
- You test the web driver under a trusted Chrome profile
Let’s test it on minggongdd:
# Instagram credentials
USERNAME = "minggongdd"
PASSWORD = "password"
and hit run!
Scraping Process
Auto login:
Loads the followers page:
Scrolls to the end of the following page:
and here’s the list:
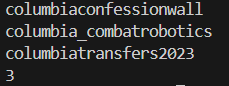
and I’ll unfollow all of them (with anger)
The whole process took about a minute for ~650 followers and following.
- Of course, this is
O(n)time, so don’t do it on, let’s say Taylor Swift :(
Obfuscated HTML elements
As mentioned before, some of the element class search keywords may become invalid after any Instagram update. If Selenium fails to locate any element, it will throw an error message, and you’ll need to F12 the webpage and find the updated class names for that element.
Current class keywords used:
- dialog: “xyi19xy”
- div: “x1dm5mii”
Conclusion
This is also an excellent demo of the power of chatGPT. I had little knowledge with web scraping or how to start the task. However, chatGPT gives a basic direction and structure of the task, greatly simplifying my learning curve.
Although GPT can’t handle the obfuscated class names, with a few tweaks in the code, I can make it working.