
2 Memory
Published:
Address Space
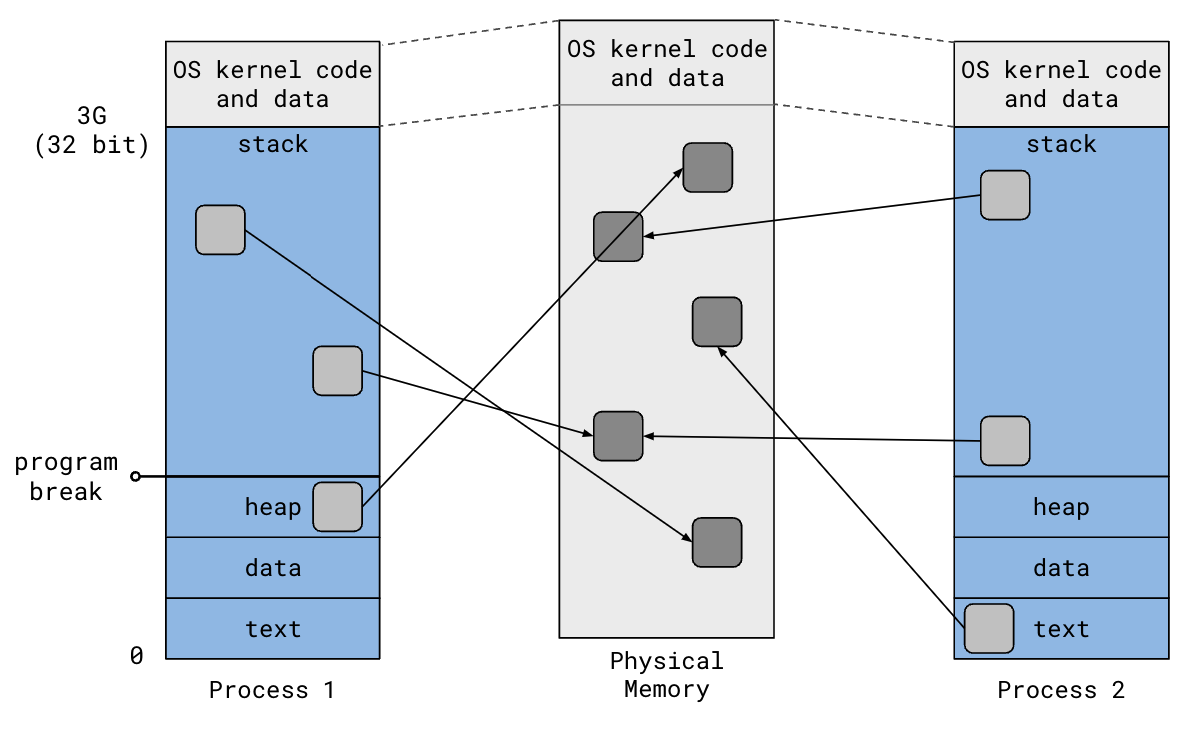
32 bit: each program uses 3G bottom. The top 1G designated for OS kernel code and data
Program break (brk, end of program): top of the heap (increasing allocates memory; decreasing deallocates), updated via brk()
- When
malloc()called, it tries to allocated a piece from heap - Library asks OS to set aside heap area
brk()system call changes program breakmalloc()andfree()then manages the new heap area- Each process thinks they own the entire process space
- Independent processes Mapping
- By chunk (page) 4096 B
- Certain VM may be mapped to the same physical memory (shared memory)
malloc() and free()
For 32-bit, block (word) is 4 bytes. All blocks align at 8-byte (double-word) boundary to ensure efficient memory access For 64-bit (ours), all blocks align to 16-byte boundaries
- Internal fragmentation: padding, when allocation > request
- External fragmentation: memory is in pieces, can’t allocate large blocks
Implicit Free List
Returns a pointer to the beginning of the payload, NOT the beginning of the allocated block
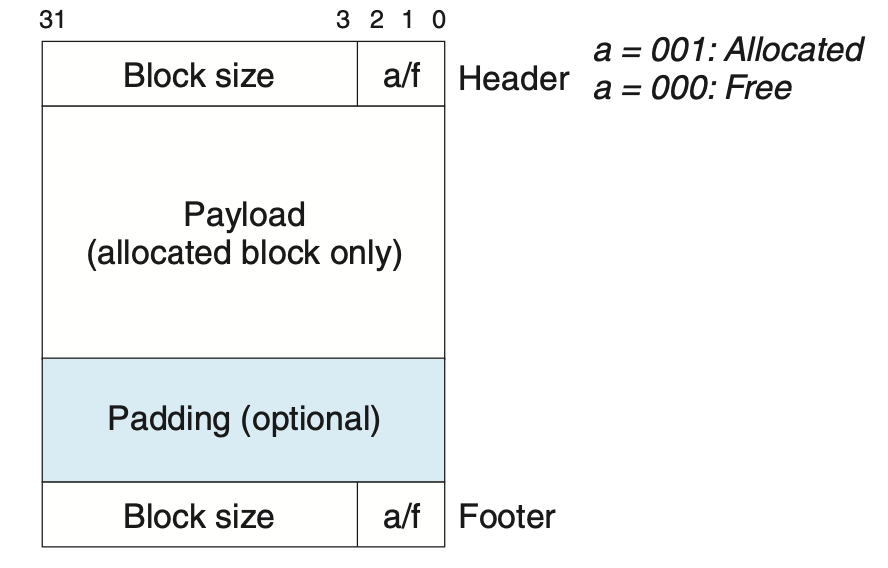
- 4-byte (1 word) header to store block size (including header)
- block size multiple of 8 (for 32b), so last 3 bits unused
- Make last bit to mark allocation
- Payload
- Padding (optional)
- Footer (same as header)
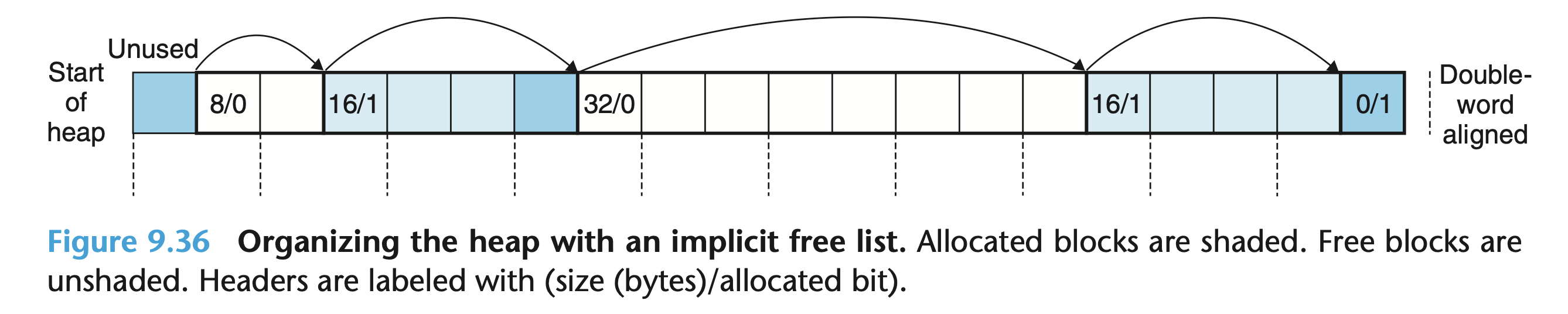
- First block unused
- Middle blocks
- 4-byte header
- Payload (double-word aligned)
- Padding (optional)
- Footer
- Last block unused (epilogue, allocated block size=0 suggests end)
char *heap_start = NULL;
// called before main()
void __init_heap() {
heap_start = sbrk(4096);
heap_start += 4; // skip prologue padding
}
void *malloc(size_t size) {
char *block = heap_start;
while (1) {
uint32_t header = *(uint32_t *)block;
size_t block_size = header & ~0x7;
int allocated = header & 0x1;
if (block_size == 0) return NULL; // epilogue reached, failed
if (!allocated && size <= block_size) { // first fit search
*(uint32_t *)block = block_size | 0x1; // take the whole block
return block + 4; // pointer to payload
}
block += block_size;
}
}
Finding Fit
- First fit
- Next fit
- Best fit
Coalescing
False fragmentation: free blocks chopped into small, unusable Need create a larger block with updated block size
- Need to reach previous and next neighbor
- Add footer to locate previous neighbor
- Minimum block size changes from 8 to 16 bytes
- The first block (header, footer, after first unused 4 bytes) becomes the prologue block
- Real allocators delay coalescing to save computation
Explicit Free List
- Implicit links all blocks. Inefficient
- Explicit uses unused free blocks to link free blocks (2 pointers) Doubly linked list (
NULLif end reached)
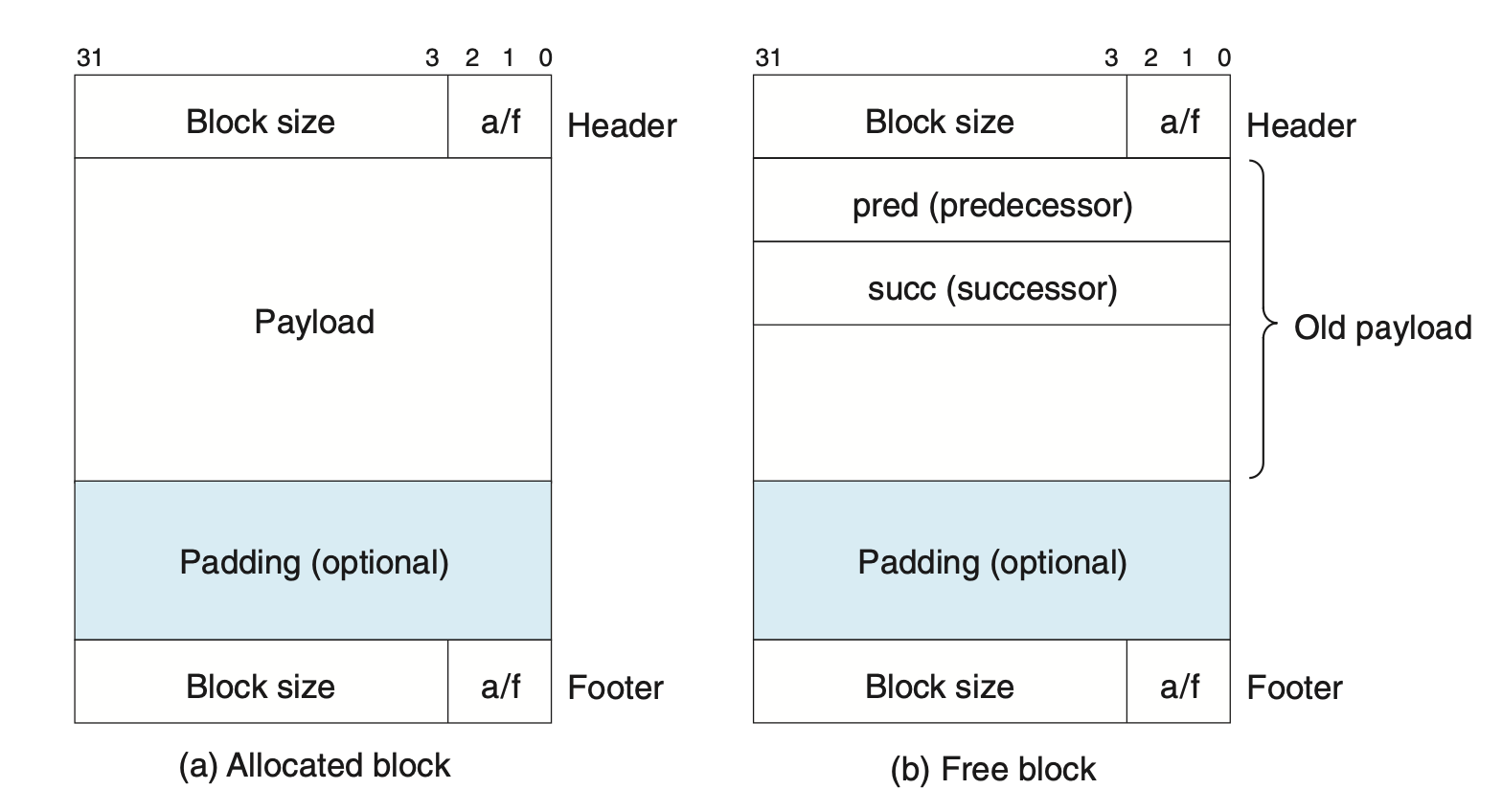

LIFO order: put newly freed blocks at the beginning of the linked list
- Exploits temporal locality
In HW, circular doubly linked list with a sentinel node
- When free list empty, sentinel node points to itself
- When not empty, sentinel’s
fnextpoints to the first node.fprevpoints to the last node Need to modify the prologue block to contain a 16-byte payload as the sentinel When coalescing, all pointers totally messed up! - Next: Take existing one from the list, coalesce it, and put it back
- Prev: easy case ???
Segregated Free Lists
Maintain multiple free lists
- Each contains blocks of similar size
Memory Mapping mmap()
mmap() system call maps a portion of the file into the address space and treat it like an array of bytes
- Alternative to
read()andwrite() - Not faster, but makes program simpler
Virtual address space(s) –(map)-> RAM space –(map)-> File
- If two processes map the same file, OS goes thru the same physical memory
- Any changes on one side will show up immediately on the other, via RAM, but not file
- RAM may interact with the file later (file IO is slow)
#include <sys/mman.h> void *mmap(void *addr, size_t length, int prot, int flag, int fd, off_t offset);Returns starting address of mapped region if OK,
MAP_FAILEDon error addr: starting address of the new mappingNULLwill letmmap()decide the starting address
length,offsetfor the fileprot: protection of the mapped region (e.g., read, write, execute)flag: optionsMAP_SHARED: Updates to the mapping are visible to other processes, and are carried through to the underlying fileMAP_PRIVATE: Updates not visible to other processes (separate RAM), and not getting into the actual file (useful for debugging)MAP_ANONYMOUS: Shared anonymous mapping. This has the effect of simply allocating memory to the process when used withMAP_PRIVATE^f7a1df- One process does
MAP_ANONYMOUSandfork(), so everything gets duplicated. Two processes share the same anonymous mapping - What’s the point of private anonymous mapping? Claim space from OS
- One process does
fd: File descriptor for the file (fromopen()). Use -1 for anonymous mapping (just two processes sharing IO)
HW 1
Padding
- Separate variables (E.
char)can start at any byte boundary - Variables in
structs are aligned to its widest member Trailing padding affects (sizeof())
Nested struct
struct foo {
char c;
char pad1[7];
struct foo_inner {
char *p;
short x;
char pad2[6];
} inner;
};
char *p forces the inner and outer struct to be pointer aligned
Bitfield
Declare structure fields of smaller than char width
- Padding may be before or after
- Bitfields can’t cross word boundary
struct foo {
int big1:63; // 64-bit word 1 begins
int big2:63; // 64-bit word 2 begins
int lil1:1;
int lil2:1; // 64-bit word 3 begins
}
Base type are interpreted for signedness, but not necessarily for size
Memory hierarchy
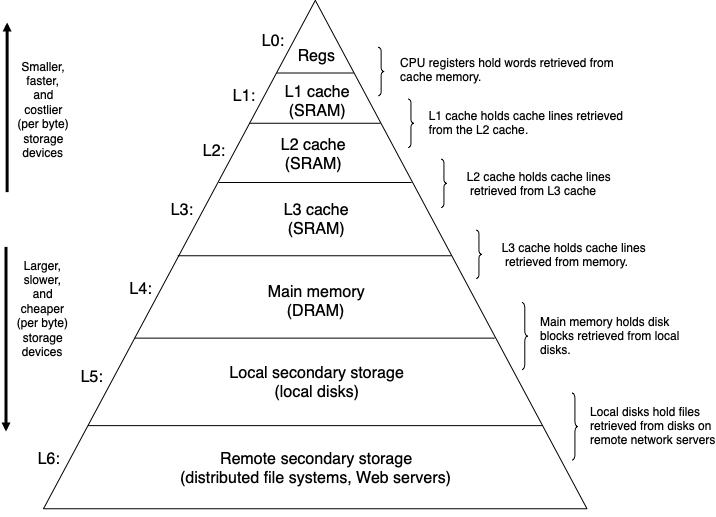
- Registers part of CPU
- Cache SRAM between registers and RAM, accessed in 64-byte block (cache lines)
- Main memory (D)RAM, 4KB pages, still volatile
- Secondary storage persistent
Cache-conscious programming (E. 2D array)
Temporal and spatial locality
int a[3][2];
+---------+---------+---------+---------+---------+---------+
| a[0][0] | a[0][1] | a[1][0] | a[1][1] | a[2][0] | a[2][1] |
+---------+---------+---------+---------+---------+---------+
Measure runtime:
time ./program
hyperfine ./program
Matrix summing
for (int i = 0; i < M; i++) {
for (int j = 0; j < N; j++) {
sum += a[i][j];
}
}
- Spatial locality: access
aone-by-one as they are in memory, which will be loaded in one cache line (stride 1) - Temporal locality:
sum,a,i,jfrequently referenced. Compilers will cache them in registers If order ofi,jswapped, then poor spatial locality (stride N)
Matrix multiplication
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
sum = 0;
for (int k = 0; k < N; k++) {
sum += a[i][k] * b[k][j];
}
c[i][j] += sum;
}
}
Assume sum is cached into a register to prevent repeatedly accessing c[i][j]; 2 loads, 0 stores
aaccessed in stride-1 (k)baccessed in stride-n (j)
for (int i = 0; i < N; i++) {
for (int k = 0; k < N; k++) {
r = a[i][k];
for (int j = 0; j < N; j++) {
c[i][j] += r * b[k][j];
}
}
}
- There are two memory loads and one memory store
bandcare both accessed in stride-1
Summary
- Optimize inner loops, which tends to dominate computation and memory access
- Strive for stride-1 for spatial locality
- Once data is read from memory, use it as much as possible for temporal
Real-life allocators
GNU libc
- Reduce contention in multi-threaded environments
- Break heap into multiple separate “arenas” for each thread
- Per-thread caching of recently freed blocks (likely to
malloc()a similar-size block)
- Handle huge requests off the heap by asking the OS kernel directly using
mmap(), which creates new page mappings for the process - Deferred coalescing: maintain fast turnaround free lists
- Segregated storage: maintain small bins holding fixed-size chunks, instead of a range Periodically shrink the heap when blocks at the top of the heap are freed
Memory Pool Allocator Specially used for frequent allocation and deallocation of the same type of object
- Allocate a large region and divide into equal-sized objects
- Eliminates external fragmentation